Kafka 中的增量协作重平衡
Kafka 中的增量协作重平衡
简介
注:本文是 Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It? 的摘录。
负载平衡和调度是每个分布式系统的核心,Apache Kafka 也不例外。Kafka 客户端——特别是 Kafka 消费者、Kafka Connect 和 Kafka Streams,这是本文的重点——从一开始就使用了一种复杂的、典型的方式来平衡资源。
按照分布式系统中的常见做法,Kafka 客户端使用组管理 API 来构建协作的客户端进程。客户端合并为组的能力来源于 Broker,它会协调客户端进组。至此 Broker 的任务就结束了。在设计中,组内的成员关系是 Broker 作为协调者所得到关于客户端的全部信息。
客户端之间的实际负载分配发生在它们之间,而不会给 Kafka Broker 带来额外的责任。客户端的负载平衡取决于组内领导客户端进程的选择以及只有客户端知道如何解释协议的定义。该协议搭载在组管理的协议中,因此称为嵌入式协议。
到目前为止,消费者、Connect 和 Streams 应用程序使用的嵌入式协议是再平衡协议,其目的是在组内有效地分配资源(用于使用记录的 Kafka 分区、Connector 任务等)。在 Kafka 组管理 API 中定义的嵌入式协议并不只是为了重平衡。这样使用嵌入式协议的方式是任何类型的分布式进程相互协调并实现其自定义逻辑的通用方式,而无需 Kafka 代理的代码知道它们的存在。
将负载平衡算法嵌入到组管理协议本身中提供了一些明显的优势:
- 自治:客户端可以独立于 Kafka 代理升级或自定义其负载平衡算法。
- 隔离:Kafka Broker 支持通用组成员 API,负载平衡的详细信息留给客户端。这简化了 Broker 的代码,并使客户端能够随意丰富其负载平衡策略。
- 更轻松的多租户:对于 Kafka 客户端(如 Kafka Connect),它们在其实例之间平衡异构资源,并且可能属于不同的用户,将此信息抽象并嵌入到重新平衡协议中,使多租户更容易在客户端级别处理。在这种情况下,多租户并不是 Broker 必须担心的另一个功能。
为了简单起见,到目前为止,所有重新平衡协议都是围绕相同的简单原则构建的:每当需要在客户端之间分配负载时,就会开始新一轮的重新平衡,在此期间,所有进程都会释放其资源。在此阶段(重新确认组成员资格并选举组的领导者)结束时,每个客户端都会被分配一组新的资源。简而言之,这也被称为停止世界再平衡(stop-the-world),这个短语可以追溯到垃圾收集文献。
停止世界再平衡的挑战
在每次重新平衡中停止世界的负载平衡算法具有某些限制,从这些越来越显着的案例中可以看出:
纵向扩展和缩减:不出所料,在重新平衡时停止世界的影响与参与过程中平衡的资源数量有关。例如,在空的 Connect 群集中启动 10 个连接任务不同于在运行 100 个现有连接任务的群集中启动相同数量的任务。
异构负载下的多租户:这里的主要示例是 Kafka Connect。当另一个连接器(可能来自其他用户)添加到群集时,停止连接器任务的副作用不仅是不希望的,而且会造成大规模破坏。
Kubernetes 进程死亡:无论是在云中还是在本地,故障都不罕见。当一个节点发生故障时,另一个节点会迅速替换它,尤其是在使用 Kubernetes 等业务流程协调程序时。理想情况下,一组 Kafka 客户端将能够吸收这种暂时的资源损失,而无需执行完全的重新平衡。节点返回后,先前分配的资源将立即分配给它。
滚动反弹:间歇性中断不仅仅是由于环境因素而偶然发生的。也可以有意将它们安排为计划升级的一部分。但是,应避免完全重新分配资源,因为缩减只是暂时的。
尽管有解决方法来适应这些用例,例如将客户端拆分为更小的组或增加与重新平衡相关的超时(这些超时往往不太灵活),但很明显,停止世界重新平衡需要用破坏性较小的方法取代。
增量合作再平衡
在 Kafka 社区中获得关注并旨在减轻当前 Eager Rebalancing 协议在大型 Kafka 客户端集群中表现出的再平衡影响的主张是增量合作再平衡。
这种新的再平衡算法的关键思想是:
- 完整的全局负载均衡不需要在一轮再均衡中完成。相反,如果客户端在连续几次重新平衡后很快收敛到平衡负载状态就足够了。
- 世界不应该被停止。不需要转手的资源不应停止使用。
当然,这些原则适合于 Kafka 客户端中改进的再平衡协议的命名。新的重新平衡是:
-
增量,因为分阶段达到重新平衡的最终期望状态。不必在每一轮再平衡结束时达到全球平衡的最终状态。可以使用少量连续的再平衡轮次,以使 Kafka 客户端组收敛到所需的平衡资源状态。此外,您可以配置宽限期,以允许离开的成员返回并重新获得其先前分配的资源。
-
合作,因为要求组中的每个进程自愿释放需要重新分配的资源。然后,如果被要求释放这些资源的客户端按时释放这些资源,则可以重新安排这些资源。
Kafka Connect 中的实现- Connect tasks 是新的线程
第一个提供增量合作再平衡协议的 Kafka 客户端是 Kafka Connect。在 Kafka Connect 中,在工作线程之间平衡的资源是连接器及其任务。连接器是一种特殊组件,主要执行与外部数据系统的协调和簿记,并充当 Kafka 记录的源或接收器。连接任务(Connect tasks)是执行实际数据传输的单元。
尽管 Connect 任务通常不会在本地存储状态,并且可以在从 Kafka 恢复状态后快速停止和恢复执行,但在每次重新平衡中停止世界可能会导致明显的延迟。在某些情况下(也称为再平衡风暴),它可能会使集群进入连续重新平衡的状态,并且 Connect 集群可能需要几分钟才能稳定下来。在增量合作再平衡之前,由于重新平衡延迟,集群可以托管的 Connect 任务数通常限制在实际容量以下,从而给人一种错误的印象,即 Connect 任务是现成的重量级实体。
使用增量协作再平衡,连接任务可以是它一直以来的用途:一个运行时执行线程,它是轻量级的,可以在 Connect 集群中的任何位置快速全局调度。
调度这些轻量级实体(可能基于特定于 Kafka Connect 的信息,例如连接器类型、所有者或任务大小等)为 Connect 提供了理想的灵活性,而不会过度扩展其职责。配置和部署工作线程是 Connect 集群的主要工具,仍然是正在使用的编排器(即 Kubernetes 或类似的基础架构)的责任。
现在让我们来看看当我们需要在 Kafka Connect 集群中重新平衡连接器和任务时会发生什么。
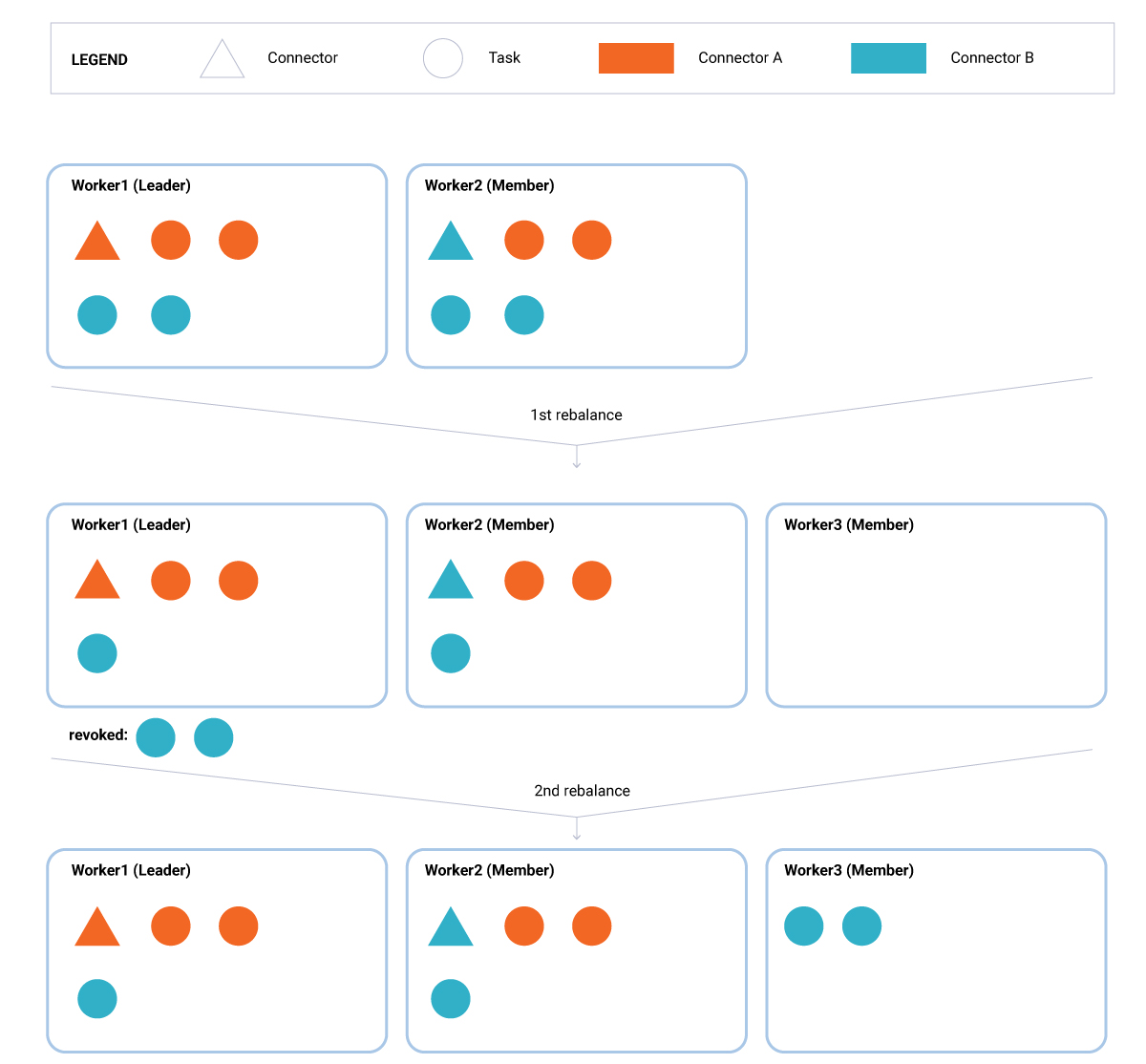
- 新节点加入(图1)。在第一次重新平衡期间,领导者(Worker1)会计算一个新的全局分配,导致每个现有工作线程(Worker1 和 Worker2)撤销一项任务。由于第一轮重新平衡包括任务吊销,因此第一次重新平衡之后会立即进行第二次重新平衡,在此期间,吊销的任务将分配给组的新成员(Worker3)。在两次重新平衡期间,未受影响的任务将继续运行而不会中断。
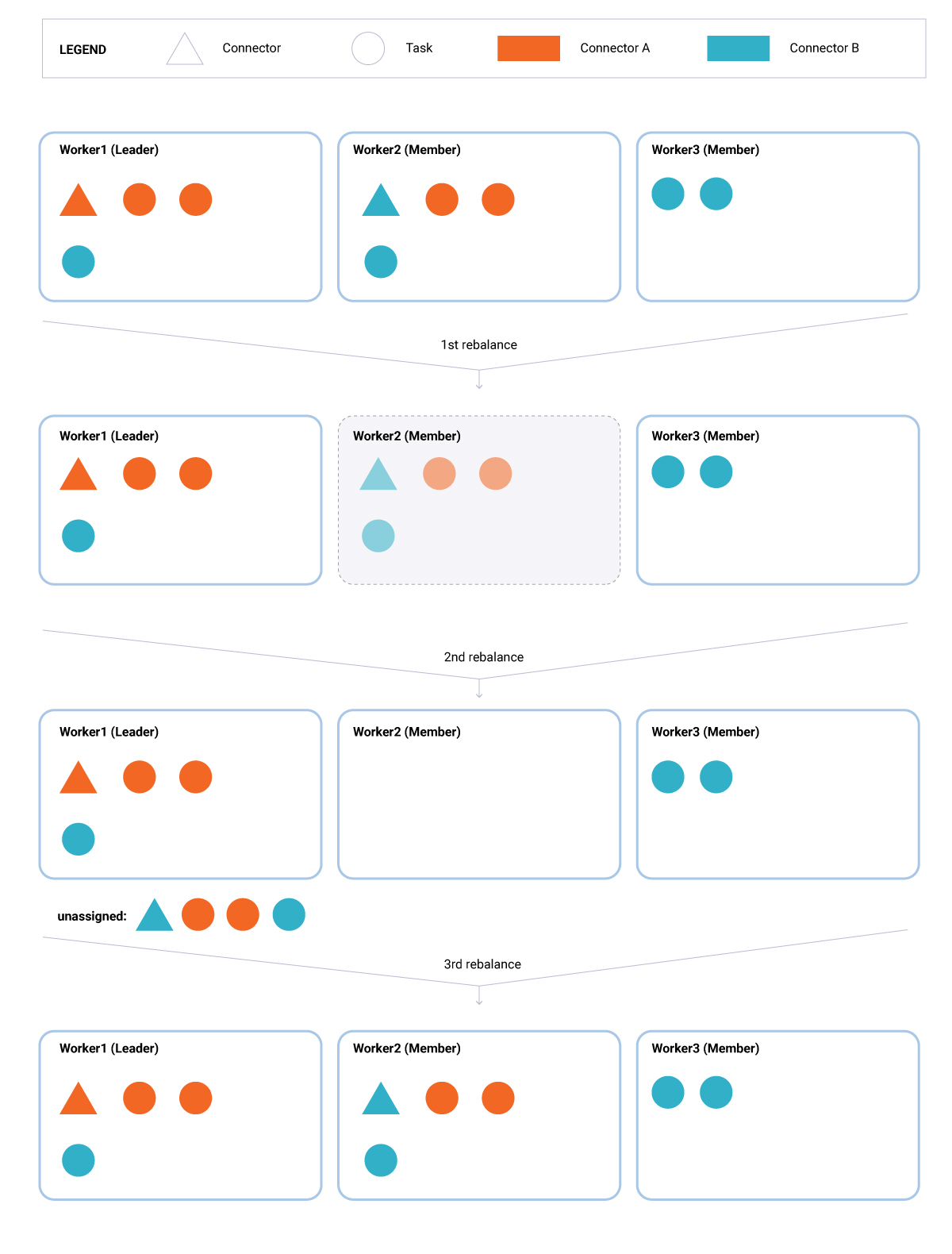
- 现有节点断开(图2)。在此方案中,节点(Worker2)离开组。它的离开触发了重新平衡。在此再平衡轮次中,领导者(Worker1)检测到与上一个分配相比缺少一个连接器和三个任务。这将启用由配置属性控制的计划的重新平衡延迟(默认情况下,它等于五分钟)。
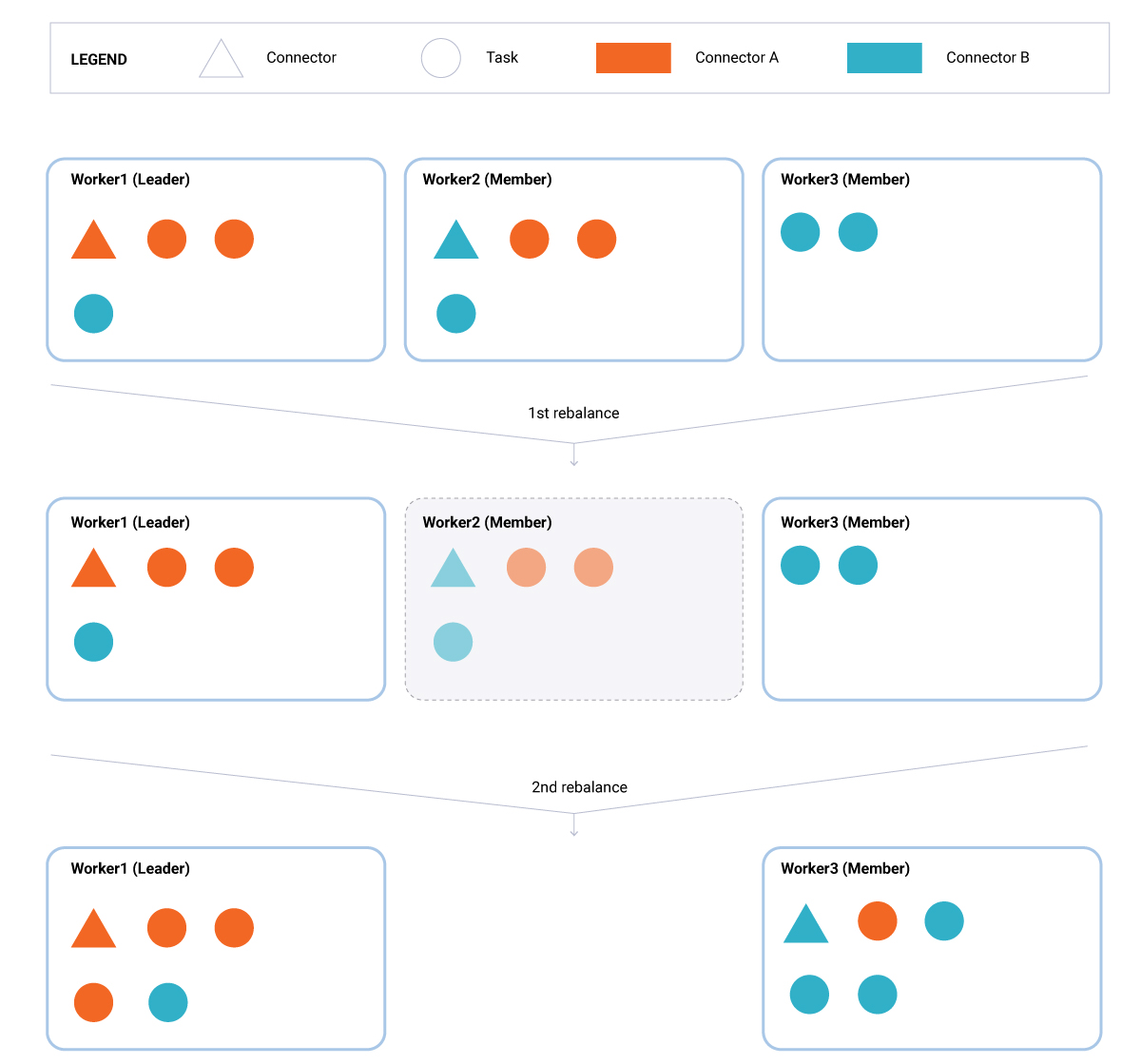
- 现有节点离开(图3)。此方案与前一个方案相同,只是此处的节点(Worker2)断开且没有及时重新加入组。在这种情况下,其任务(一个连接器和三个任务)在等于
scheduled.rebalance.max.delay.ms的时间内保持未分配状态。之后,剩余的两个节点(Worker1 和Worker3)重新加入组,领导者将计划再平衡延迟期间未计算的任务重新分配给现有的活动节点集(Worker1 和Worker3)。
参考资料
Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It?