Impala: A Modern, Open-Source SQL Engine for Hadoop 中文翻译
Impala: A Modern, Open-Source SQL Engine for Hadoop
作者:Marcel Kornacker, Alexander Behm, Victor Bittorf, Taras Bobrovytsky, Casey Ching, Alan Choi, Justin Erickson, Martin Grund, Daniel Hecht, Matthew Jacobs, Ishaan Joshi, Lenni Kuff, Dileep Kumar, Alex Leblang, Nong Li, Ippokratis Pandis, Henry Robinson, David Rorke, Silvius Rus, John Russell, Dimitris Tsirogiannis, Skye Wanderman-Milne, Michael Yoder
版权说明
1 | |
简介
Cloudera Impala 是一个现代的、开源的 MPP SQL 引擎,专为 Hadoop 数据处理环境而设计。 Impala 为 Hadoop 上的 BI/分析以读取为主的查询提供低延迟和高并发,而不是由 Apache Hive 等批处理框架提供。 本文从用户的角度介绍 Impala,概述其架构和主要组件,并简要展示其与其他流行的 SQL-on-Hadoop 系统相比的卓越性能。
1 引言
Impala 是一个开源的、完全集成的、先进的 MPP SQL 查询引擎,专为利用 Hadoop 的灵活性和可扩展性而设计。 Impala 的目标是将熟悉的 SQL 支持和传统分析数据库的多用户性能与 Apache Hadoop 的可扩展性和灵活性以及 Cloudera Enterprise 的生产级安全和管理扩展相结合。 Impala 的 beta 版本于 2012 年 10 月发布,并于 2013 年 5 月 GA 发布。最新版本 Impala 2.0 于 2014 年 10 月发布。Impala 的生态系统势头继续加速,自 GA 以来下载量接近 100 万次。
与其他系统(通常是 Postgres 的分支)不同,Impala 是一个全新的引擎,使用 C++ 和 Java 从头开始编写。 它通过使用标准组件(HDFS、HBase、Metastore、YARN、Sentry)来保持 Hadoop 的灵活性,并且能够读取大多数广泛使用的文件格式(例如 Parquet、Avro、RCFile)。 为了减少延迟,例如使用 MapReduce 或远程读取数据所产生的延迟,Impala 实现了一个基于守护进程的分布式架构,这些进程负责查询执行的所有方面,并且与 Hadoop 基础架构的其余部分在同一台机器上运行。 结果是性能相当或超过商业 MPP 分析 DBMS,具体取决于特定的工作负载。
本文讨论 Impala 为用户提供的服务,然后概述其架构和主要组件。 当今可实现的最高性能需要使用 HDFS 作为底层存储管理器,因此这是本文的重点;当某些技术方面如何与 HBase 一起处理方面存在显着差异时,我们会在文本中说明而不会深入细节。
Impala 是性能最高的 SQL-on-Hadoop 系统,尤其是在多用户工作负载下。 如第 7 节所示,对于单用户查询,Impala 比替代方案快 13 倍,平均快 6.7 倍。 对于多用户查询,差距越来越大:Impala 比替代方案快 27.4 倍,平均快 18 倍——多用户查询的平均速度是单用户查询的近三倍。
本文的其余部分结构如下:下一节从用户的角度对 Impala 进行概述,并指出它与传统 RDBMS 的不同之处。 第 3 节介绍了系统的整体架构。第 4 节介绍了前端组件,其中包括基于成本的分布式查询优化器,第 5 节介绍了负责查询执行并使用运行时代码生成的后端组件,第 6 节介绍了资源/工作负载管理组件。 7 节简要评估了 Impala 的性能。第 8 节讨论了未来的路线图,第 9 节得出结论。
2 IMPALA 的用户视图
Impala 是一个集成到 Hadoop 环境中的查询引擎,它利用许多标准 Hadoop 组件(Metastore、HDFS、HBase、YARN、Sentry)来提供类似 RDBMS 的体验。 但是,本节的其余部分将提出一些重要的区别。
Impala 专门针对与标准商业智能环境的集成,并为此支持大多数相关的行业标准:客户端可以通过 ODBC 或 JDBC 进行连接;使用 Kerberos 或 LDAP 完成身份验证;授权遵循标准的 SQL 角色和权限。 为了查询 HDFS 驻留的数据,用户通过熟悉的 CREATE TABLE 语句创建表,该语句除了提供数据的逻辑模式外,还指示物理布局,例如文件格式和在 HDFS 目录结构。 然后可以使用标准 SQL 语法查询这些表。
2.1 物理结构设计
创建表时,用户还可以指定一些分区列:
1 | |
对于未分区的表,数据文件默认直接存储在根目录中<3>。对于分区表,数据文件放置在其路径反映分区列值的子目录中。
例如,对于表 T 的第 2 个月第 17 天,所有数据文件都将位于目录 <root>/day=17/month=2/ 中。
请注意,这种形式的分区并不意味着单个分区的数据的搭配:一个分区的数据文件块随机分布在 HDFS 数据节点上。
注 3:但是,位于根目录下的任何目录中的所有数据文件都是表数据集的一部分。这是处理未分区表的常用方法,Apache Hive 也采用了这种方法。
在选择文件格式时,Impala 还为用户提供了很大的灵活性。
它目前支持压缩和未压缩的文本文件、序列文件(文本文件的可拆分形式)、RCFile(传统的列格式)、Avro(二进制行格式)和 Parquet,这是最高性能的存储选项(第 5.3 节会更详细的要论文件类型)。
如上例,用户在 CREATE TABLE 或 ALTER TABLE 语句中指明存储格式。也可以为每个分区单独选择单独的格式。
例如,可以使用以下命令专门将特定分区的文件格式设置为 Parquet:ALTER TABLE PARTITION(day=17, month=2) SET FILEFORMAT PARQUET。
作为一个有用的例子,考虑一个按时间顺序记录数据的表,例如点击日志。当天的数据可能以 CSV 文件的形式出现,并在每天结束时批量转换为 Parquet。
2.2 SQL 支持
Impala 支持大多数 SQL-92 SELECT 语句语法,以及附加的 SQL-2003 分析函数,以及大多数标准标量数据类型:整型和浮点型、STRING、CHAR、VARCHAR、TIMESTAMP 和精度高达 38 位的 DECIMAL。 自定义应用程序逻辑可以通过 Java 和 C++ 中的用户定义函数 (UDF) 以及当前仅在 C++ 中的用户定义聚合函数 (UDA) 进行合并。
由于 HDFS 作为存储管理器的限制,Impala 不支持 UPDATE 或 DELETE,本质上只支持批量插入(INSERT INTO … SELECT …) <4>。
与传统 RDBMS 不同,用户只需使用 HDFS 的 API 将数据文件复制/移动到该表的目录位置,即可将数据添加到表中。 或者,同样可以使用 LOAD DATA 语句来完成。
注 4:我们还应该注意 Impala 支持 VALUES 子句。但是,对于 HDFS 支持的表,这将在每个 INSERT 语句生成一个文件,这会导致大多数应用程序的性能非常差。对于 HBase 支持的表,VALUES 变体通过 HBase API 执行单行插入。
与批量插入类似,Impala 通过删除表分区(ALTER TABLE DROP PARTITION)支持批量数据删除。因为不可能就地更新 HDFS 文件,所以 Impala 不支持 UPDATE 语句。 相反,用户通常会重新计算部分数据集以合并更新,然后替换相应的数据文件,通常是通过删除和重新添加分区。
在初始数据加载之后,或者每当表的大部分数据发生变化时,用户应该运行 COMPUTE STATS <table> 语句,该语句指示 Impala 收集表的统计信息。这些统计信息随后将在查询优化期间使用。
3 架构
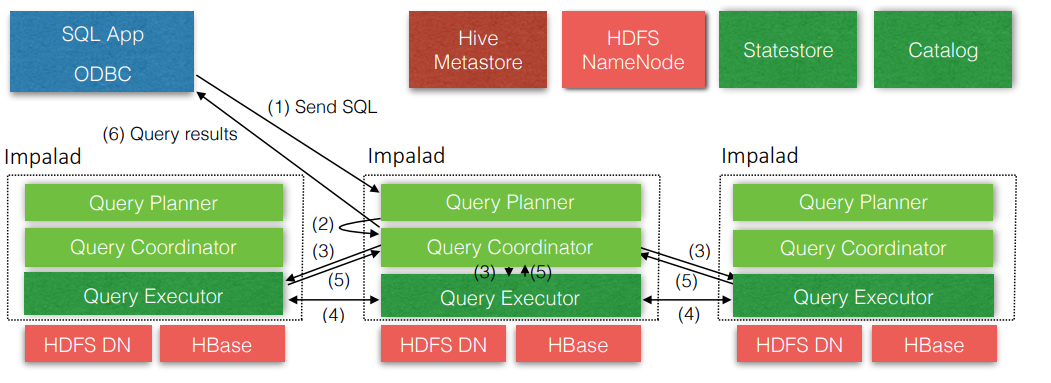
Impala 是一个大规模并行查询执行引擎,它运行在现有 Hadoop 集群中的数百台机器上。 它与底层存储引擎分离,与传统的关系数据库管理系统不同,后者的查询处理和底层存储引擎是单个紧密耦合系统的组件。Impala 的高级架构如图 1 所示。
Impala 部署由三个服务组成。Impala 守护进程 (impalad) 服务双重负责接受来自客户端进程的查询并协调它们在集群中的执行,以及代表其他 Impala 守护进程执行单个查询片段。 当 Impala 守护进程通过管理查询执行以第一个角色运行时,它被称为该查询的协调者。然而,所有 Impala 守护进程都是对称的;他们可能都扮演所有角色。此属性有助于容错和负载平衡。
一个 Impala 守护进程部署在集群中的每台机器上,这些机器也运行一个 datanode 进程——底层 HDFS 部署的块服务器——因此每台机器上通常都有一个 Impala 守护进程。 这使 Impala 可以利用数据局部性,并从文件系统中读取块,而无需使用网络。
Statestore 守护进程(statestored)是 Impala 的元数据发布订阅服务,它将集群范围的元数据传播到所有 Impala 进程。 有一个单独的 statestored 实例,在下面的 3.1 节中有更详细的描述。
最后,3.2 节中描述的目录守护进程(catalogd)用作 Impala 的目录存储库和元数据访问网关。 通过 catalogd,Impala 守护程序可以执行反映在外部目录存储(例如 Hive Metastore)中的 DDL 命令。对系统目录的更改通过 statestore 广播。
所有这些 Impala 服务以及几个配置选项,例如资源池的大小、可用内存等。 (有关资源和工作负载管理的更多详细信息,请参阅第 6 节)也暴露给 Cloudera Manager,这是一个复杂的 集群管理应用。 Cloudera Manager 不仅可以管理 Impala,还可以管理几乎所有服务,以全面了解 Hadoop 部署。
3.1 状态分发
旨在在数百个节点上运行的 MPP 数据库设计中的一个主要挑战是集群范围元数据的协调和同步。 Impala 的对称节点架构要求所有节点都必须能够接受和执行查询。因此,所有节点都必须拥有最新版本的系统目录和 Impala 集群成员的最新视图,以便可以正确安排查询。
我们可以通过部署一个单独的集群管理服务来解决这个问题,其中包含所有集群范围元数据的真实版本。 Impala 守护进程可以延迟查询这个存储(即仅在需要时),这将确保所有查询都得到最新的响应。 然而,Impala 设计的一个基本原则是在任何查询的关键路径上尽可能避免同步 RPC。 在没有密切关注这些成本的情况下,我们发现查询延迟通常会因建立 TCP 连接或加载某些远程服务所花费的时间而受到影响。 相反,我们将 Impala 设计为向所有相关方推送更新,并设计了一个名为 statestore 的简单发布-订阅服务来将元数据更改传播给一组订阅者。
statestore 维护一组主题,它们是(键、值、版本)三元组的数组,称为条目,其中“键”和“值”是字节数组,“版本”是 64 位整数。 主题由应用程序定义,因此 statestore 不了解任何主题条目的内容。主题在 statestore 的整个生命周期中都是持久的,但不会在服务重新启动时持久。 希望接收任何主题更新的进程称为订阅者,并通过在启动时向 statestore 注册并提供主题列表来表达他们的兴趣。 statestore 通过向订阅者发送每个已注册主题的初始主题更新来响应注册,其中包含当前在该主题中的所有条目。
注册后,statestore 会定期向每个订阅者发送两种消息。第一种消息是主题更新,包括自上次更新成功发送给订阅者以来对主题的所有更改(新条目、修改的条目和删除)。 每个订阅者都维护一个每个主题的最新版本标识符,它允许 statestore 仅在更新之间发送增量。作为对主题更新的响应,每个订阅者都会发送一份希望对其订阅主题进行更改的列表。 保证在收到下一次更新时已应用这些更改。
第二种 statestore 消息是 keepalive。statestore 使用 keepalive 消息来维护与每个订阅者的连接,否则订阅会超时并尝试重新注册。 以前版本的 statestore 将主题更新消息用于这两个目的,但随着主题更新规模的增长,很难确保及时向每个订阅者传递更新,从而导致订阅者的故障检测过程中出现误报。
如果 statestore 检测到失败的订阅者(例如,通过重复失败的 keepalive 交付),它将停止发送更新。 一些主题条目可能被标记为“临时”,这意味着如果他们的“拥有”订阅者失败,他们将被删除。 这是一个自然的原语,用于在专用主题中维护集群的活跃度信息,以及每个节点的负载统计信息。
statestore 提供了非常弱的语义:订阅者可能以不同的速率更新(尽管 statestore 尝试公平地分发主题更新),因此可能对主题内容有非常不同的看法。 但是,Impala 仅使用主题元数据在本地做出决策,而无需跨集群进行任何协调。 例如,查询计划是基于目录元数据主题在单个节点上执行的,一旦计算出完整的计划,执行该计划所需的所有信息都会直接分发给执行节点。 执行节点不需要知道目录元数据主题的相同版本。
尽管现有 Impala 部署中只有一个 statestore 进程,但我们发现它可以很好地扩展到中型集群,并且通过一些配置,可以服务于我们最大的部署。 statestore 不会将任何元数据保存到磁盘:所有当前元数据都由实时订阅者推送到 statestore(例如加载信息)。 因此,如果 statestore 重新启动,它的状态可以在初始订阅者注册阶段恢复。 或者,如果运行 statestore 的机器发生故障,则可以在其他地方启动新的 statestore 进程,并且订阅者可能会故障转移到它。 Impala 中没有内置的故障转移机制,而是部署通常使用可重定向的 DNS 条目来强制订阅者自动移动到新的流程实例。
3.2 目录服务
Impala 的目录服务通过 statestore 广播机制为 Impala 守护进程提供目录元数据,并代表 Impala 守护进程执行 DDL 操作。 目录服务从第三方元数据存储(例如,Hive Metastore 或 HDFS Namenode)中提取信息,并将该信息聚合到 Impala 兼容的目录结构中。 这种架构允许 Impala 对其所依赖的存储引擎的元数据存储相对不可知,这允许我们相对快速地将新的元数据存储添加到 Impala(例如 HBase 支持)。 对系统目录的任何更改(例如,当加载新表时)都会通过 statestore 传播。
目录服务还允许我们使用特定于 Impala 的信息来扩充系统目录。 例如,我们仅向目录服务注册用户定义的函数(例如,不将其复制到 Hive Metastore),因为它们特定于 Impala。
由于目录通常非常大,而且对表的访问很少是统一的,因此目录服务只会为它在启动时发现的每个表加载一个框架条目。 更详细的表元数据可以从其第三方商店在后台延迟加载。如果在完全加载之前需要一个表,Impala 守护程序将检测到这一点并向目录服务发出优先级请求。此请求会阻塞,直到表完全加载。
4 前端
Impala 前端负责将 SQL 文本编译成 Impala 后端可执行的查询计划。它是用 Java 编写的,由功能齐全的 SQL 解析器和基于成本的查询优化器组成,所有这些都是从头开始实现的。 除了基本的 SQL 功能(select、project、join、group by、order by、limit)之外,Impala 还支持内联视图、不相关和相关子查询(被重写为连接)、外连接的所有变体以及显式左/右 半链接和反连接,以及分析窗口函数。
查询编译过程遵循传统的分工:查询解析、语义分析和查询规划/优化。我们将专注于查询编译中最具挑战性的后者部分。 Impala 查询计划器作为输入提供一个解析树以及在语义分析期间组装的查询全局信息(表/列标识符、等价类等)。 可执行查询计划的构建分为两个阶段:(1)单节点计划和(2)计划并行化和分片。
第一阶段,解析树被翻译成一个不可执行的单节点计划树,由以下计划节点组成:HDFS/HBase scan、hash join、cross join、union、hash aggregation、sort、top-n、分析评估。 此步骤负责在可能的最低损耗的节点分配谓词、基于等价类推断谓词、修剪表分区、设置限制/偏移量、应用列投影,以及执行一些基于成本的计划优化,例如排序和合并分析 窗口函数和连接重新排序以最小化总评估成本。 成本估算基于表/分区基数加上每列的不同值计数<6>;直方图目前不是统计数据的一部分。Impala 使用简单的启发式方法来避免在常见情况下详尽地枚举和计算整个连接顺序空间。
注 6:我们使用 HyperLogLog 算法
[5]进行不同的估值。
第二阶段将单节点计划作为输入,并产生一个分布式执行计划。总体目标是最小化数据移动并最大化扫描局部性:在 HDFS 中,远程读取比本地读取慢得多。 通过根据需要在计划节点之间添加交换节点,并通过添加额外的非交换计划节点来最小化跨网络的数据移动(例如,本地聚合节点),从而使计划成为分布式的。 在第二阶段,我们决定每个连接节点的连接策略(此时连接顺序是固定的)。支持的连接策略是广播和分区的。 前者将连接的整个构建端复制到所有执行探测的集群机器上,后者在连接表达式上重新分配构建端和探测端。 Impala 选择估计的任何策略以最小化通过网络交换的数据量,同时利用连接输入的现有数据分区。
所有聚合当前都作为本地预聚合执行,然后合并聚合操作。对于分组聚合,预聚合输出在分组表达式上进行分区,合并聚合在所有参与节点上并行完成。 对于非分组聚合,合并聚合在单个节点上完成。sort 和 top-n 以类似的方式并行化:分布式本地排序/top-n 之后是单节点合并操作。 分析表达式评估是基于 partition-by 表达式并行化的。它依赖于根据 partition-by/order-by 表达式对输入进行排序。 最后,分布式计划树在交换边界处被拆分。计划的每个这样的部分都放置在计划片段中,即 Impala 的后端执行单元。 计划片段封装了计划树的一部分,该部分在单台机器上的相同数据分区上运行。
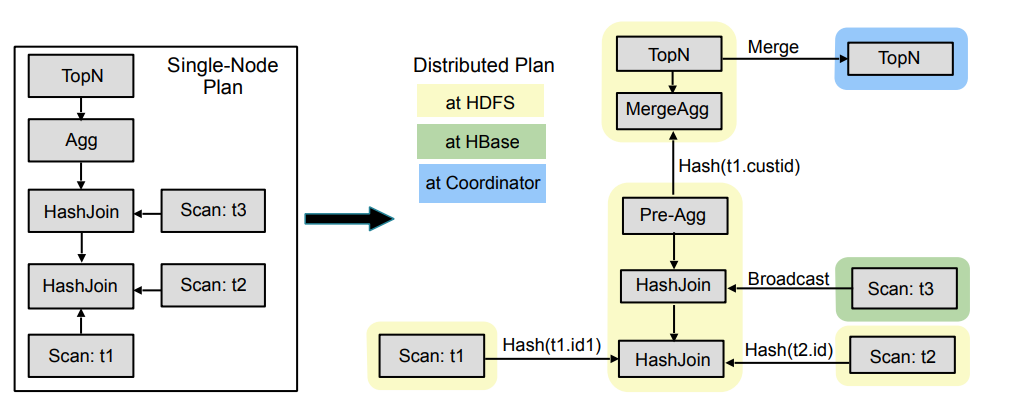
图 2 举例说明了查询计划的两个阶段。该图的左侧显示了一个查询的单节点计划,该查询连接了两个 HDFS 表(t1,t2)和一个 HBase 表(t3),然后是一个聚合和 order by with limit(top-n)。
右侧显示了分散的、分散的计划。圆角矩形表示片段边界和箭头数据交换。表 t1 和 t2 通过分区策略连接。
扫描位于它们自己的片段中,因为它们的结果会立即交换给消费者(连接节点),消费者(连接节点)在基于散列的数据分区上运行,而表数据是随机分区的。
以下与 t3 的连接是广播连接,与 t1 和 t2 之间的连接放置在同一片段中,因为广播连接保留了现有的数据分区(连接 t1、t2 和 t3 的结果仍然是基于连接键的哈希分区 t1 和 t2)。
在连接之后,我们执行两阶段分布式聚合,其中预聚合在与最后一个连接相同的片段中计算。预聚合结果基于分组键进行哈希交换,然后再次聚合以计算最终聚合结果。
相同的两阶段方法应用于 top-n,最后的 top-n 步骤在协调器处执行,协调器将结果返回给用户。
5 后端
Impala 的后端从前端接收查询片段并负责它们的快速执行。它旨在充分利用现代硬件。 后端是用 C++ 编写的,并在运行时使用代码生成来生成有效的代码路径(相对于指令数)和较小的内存开销,尤其是与用 Java 实现的其他引擎相比。
Impala 利用了数十年来对并行数据库的研究。执行模型是具有 Exchange 运算符的传统 Volcano 样式 [7]。处理是分批执行的:每个 GetNext() 调用对成批的行进行操作,类似于 [10]。
除了“走走停停(stop-and-go)”操作符(例如排序)外,执行是完全可流水线的,这最大限度地减少了存储中间结果的内存消耗。
可能需要消耗大量内存的操作员被设计为能够在需要时将部分工作集溢写到磁盘。可溢出的运算符是散列连接、(基于散列的)聚合、排序和分析函数的评估。
Impala 对散列连接和聚合运算符采用分区方法。也就是说,每个元组的哈希值的一些位确定目标分区,其余位用于哈希表探测。 在正常操作期间,当所有哈希表都适合内存时,分区步骤的开销最小,在不可溢出的非基于分区的实现的性能的 10% 以内。 当存在内存压力时,“受害者”分区可能会溢出到磁盘,从而释放内存以供其他分区完成处理。 当为哈希连接构建哈希表并且构建端关系的基数减少时,我们构建了一个布隆过滤器,然后将其传递给探测端扫描器,实现半连接的简单版本。
5.1 运行时代码生成
使用 LLVM [8] 生成运行时代码是 Impala 后端广泛采用的用于缩短执行时间的技术之一。典型工作负载通常会获得 5 倍或更多的性能提升。
LLVM 是一个编译器库和相关工具的集合。与作为独立应用程序实现的传统编译器不同,LLVM 被设计为模块化和可重用的。 它允许像 Impala 这样的应用程序在正在运行的进程中执行即时(JIT)编译,具有现代优化器的全部优势以及为多种架构生成机器代码的能力,通过为编译的所有步骤公开单独的 API 过程。
Impala 使用运行时代码生成来生成对性能至关重要的特定查询版本的函数。特别是,代码生成应用于“内循环”函数,即在给定查询中多次执行(对于每个元组)的函数,因此构成了查询执行总时间的很大一部分。 例如,用于将数据文件中的记录解析为 Impala 内存中元组格式的函数必须为扫描的每个数据文件中的每条记录调用。对于扫描大型表的查询,这可能是数十亿或更多的记录。 因此,该函数必须非常高效才能获得良好的查询性能,即使从函数执行中删除一些指令也会导致查询速度大幅提升。
如果没有代码生成,函数执行时为了处理程序编译时未知的运行时信息而导致低效率几乎总是必定的。 例如,仅处理整数类型的记录解析函数在解析仅整数文件时将比处理其他数据类型(如字符串和浮点数)的函数更快。 但是,要扫描的文件的模式在编译时是未知的,因此必须使用通用函数,即使在运行时已知更有限的功能就足够了。
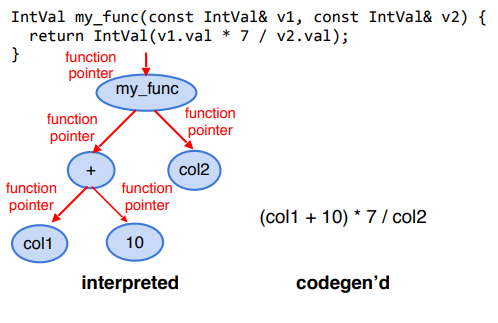
大量运行时的开销都来源于虚函数。虚函数调用会导致很大的性能损失,特别是当被调用函数非常简单时,因为调用不能内联。 如果对象实例的类型在运行时已知,我们可以使用代码生成将虚函数调用替换为直接调用正确的函数,然后可以内联。 这在评估表达式树时特别有价值。在 Impala 中(就像在许多系统中一样),表达式由单个运算符和函数的树组成,如图 3 的左侧所示。 可以出现在树中的每种类型的表达式都是通过重写表达式基类中的虚函数来实现的,该虚函数递归地调用其子表达式。其中许多表达式函数非常简单,例如,将两个数字相加。 因此,调用虚函数的成本往往远远超过实际评估函数的成本。如图 3 所示,通过使用代码生成解析虚函数调用,然后内联生成的函数调用,可以直接评估表达式树,而无需函数调用开销。 此外,内联函数增加了指令级并行性,并允许编译器进行进一步的优化,例如跨表达式消除子表达式。
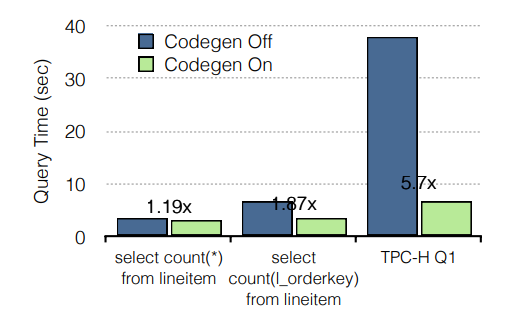
总的来说,JIT 编译的效果类似于自定义编码查询。例如,它消除了分支、展开循环、传播常量、偏移量和指针、内联函数。代码生成对性能有显着影响,如图 4 所示。 例如,在一个 10 节点集群中,每个节点有 8 个内核、48GB RAM 和 12 个磁盘,我们测量了运行时代码生成造成的影响。 我们正在使用比例因子为 100 的 Avro TPC-H 数据库,并运行简单的聚合查询。代码生成将执行速度提高了 5.7 倍,速度随着查询复杂度的增加而增加。
5.2 I/O 管理
高效地从 HDFS 检索数据是所有 SQL-on-Hadoop 系统的挑战。为了以或接近硬件速度从磁盘和内存执行数据扫描,Impala 使用称为短路本地读取 [3] 的 HDFS 功能在从本地磁盘读取时绕过 DataNode 协议。
Impala 几乎可以以磁盘带宽(每个磁盘大约 100MB/s)进行读取,并且通常能够使所有可用磁盘饱和。我们测量了 12 个磁盘,Impala 能够维持 1.2GB/秒的 I/O。
此外,HDFS 缓存 [2] 允许 Impala 以内存总线速度访问内存驻留数据,并且还节省了 CPU 周期,因为不需要复制数据块和/或校验它们。
从/向存储设备读取/写入数据是 I/O 管理器组件的职责。
I/O 管理器为每个物理磁盘分配固定数量的工作线程(每个旋转磁盘一个线程,每个 SSD 八个),为客户端提供异步接口(例如扫描程序线程)。
Impala 的 I/O 管理器的有效性最近得到了 [6] 的证实,这表明 Impala 的读取吞吐量比其他测试系统高 4 倍到 8 倍。
5.3 存储格式
Impala 支持最流行的文件格式:Avro、RC、Sequence、纯文本和 Parquet。这些格式可以与不同的压缩算法结合使用,例如 snappy、gzip、bz2。
在大多数用例中,我们建议使用 Apache Parquet,这是一种最先进的开源列式文件格式,可提供高压缩和高扫描效率。 它由 Twitter 和 Cloudera 在 Criteo、Stripe、Berkeley AMPlab 和 LinkedIn 的贡献下共同开发。 除了 Impala,大多数基于 Hadoop 的处理框架,包括 Hive、Pig、MapReduce 和 Cascading 都能够处理 Parquet。
简单地说,Parquet 是一种可定制的类 PAX [1] 格式,针对大型数据块(数十、数百、数千兆字节)进行了优化,并内置了对嵌套数据的支持。
受 Dremel 的 ColumnIO 格式 [9] 的启发,Parquet 按列存储嵌套字段,并用最少的信息对其进行扩充,以便在扫描时从列数据中重新组装嵌套结构。
Parquet 具有一组可扩展的列编码。1.2 版支持运行长度和字典编码,2.0 版增加了对增量和优化字符串编码的支持。
最新版本(Parquet 2.0)还实现了嵌入式统计:内联列统计以进一步优化扫描效率,例如最小/最大索引。
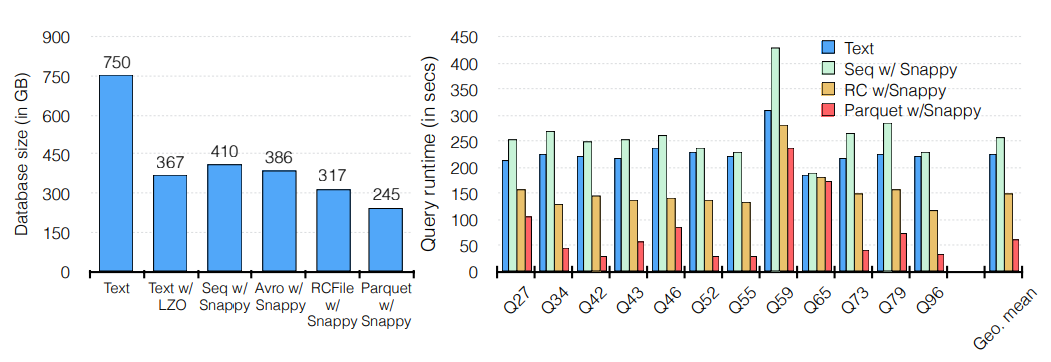
如前所述,Parquet 提供高压缩和扫描效率。图 5 (左)比较了比例因子为 1,000 的 TPC-H 数据库的 Lineitem 表在以一些流行的文件格式和压缩算法组合存储时的磁盘大小。 采用 snappy 压缩的 Parquet 实现了其中最好的压缩。同样,图 5 (右)显示了当数据库以纯文本、序列、RC 和 Parquet 格式存储时,来自 TPC-DS 基准的各种查询的 Impala 执行时间。 Parquet 的性能始终优于所有其他格式的 5 倍。
6 资源/负载管理
任何集群框架的主要挑战之一是仔细控制资源消耗。Impala 通常在繁忙的集群环境中运行,其中 MapReduce 任务、摄取作业和定制框架竞争有限的 CPU、内存和网络资源。 困难在于在不影响查询延迟或吞吐量的情况下协调查询之间以及可能在框架之间的资源调度。
Apache YARN [12] 是 Hadoop 集群上资源中介的当前标准,它允许框架共享 CPU 和内存等资源,而无需对集群进行分区。
YARN 有一个集中式架构,其中框架请求 CPU 和内存资源,这些资源由中央资源管理器服务进行仲裁。
这种架构的优点是允许在完全了解集群状态的情况下做出决策,但它也对资源获取造成了很大的延迟。
由于 Impala 以每秒数千次查询的工作负载为目标,我们发现资源请求和响应周期过长。
我们解决这个问题的方法有两个:首先,我们实现了一个互补但独立的准入控制机制,允许用户控制他们的工作负载,而无需昂贵的集中决策。 其次,我们在 Impala 和 YARN 之间设计了一个中介服务,目的是纠正一些阻抗不匹配。 该服务称为 Llama for Low-Latency Application MAster,它实现了资源缓存、组调度和增量分配更改,同时仍将实际调度决策推迟到 YARN 以处理未命中 Llama 缓存的资源请求。
本节的其余部分描述了使用 Impala 进行资源管理的两种方法。我们的长期目标是通过支持准入控制的低延迟决策制定和 YARN 的跨框架支持的单一机制来支持混合工作负载资源管理。
6.1 Llama 和 YARN
Llama 是一个独立的守护进程,所有 Impala 守护进程都向其发送每个查询的资源请求。每个资源请求都与一个资源池相关联,该资源池定义了查询可能使用的集群可用资源的公平份额。
如果资源池的资源在 Llama 的资源缓存中可用,Llama 会立即将它们返回给查询。这种快速路径允许 Llama 在资源争用较低时绕过 YARN 的资源分配算法。 否则,Llama 将请求转发给 YARN 的资源管理器,并等待所有资源返回。这与 YARN 的“滴灌”分配模型不同,后者在分配资源时返回资源。 Impala 的流水线执行模型要求所有资源同时可用,以便所有查询片段可以并行进行。
由于查询计划的资源估计,特别是在非常大的数据集上,通常是不准确的,我们允许 Impala 查询在执行期间调整其资源消耗估计。 YARN 不支持这种模式,相反,我们让 Llama 向 YARN 发出新的资源请求(例如,要求每个节点多 1GB 的内存),然后从 Impala 的角度将它们聚合到单个资源分配中。 这种适配器架构允许 Impala 与 YARN 完全集成,而无需自己承担处理不合适的编程接口的复杂性。
6.2 准入控制
除了与 YARN 集成以进行集群范围的资源管理之外,Impala 还具有内置的准入控制机制来限制传入请求。 请求被分配到资源池,并根据定义每个池的最大并发请求数和请求的最大内存使用量限制的策略来接受、排队或拒绝。 准入控制器被设计为快速和分散的,因此可以准入任何 Impala 守护程序的传入请求,而无需向中央服务器发出同步请求。 做出准入决定所需的状态通过 statestore 在 Impala 守护进程之间传播,因此每个 Impala 守护进程都能够基于其对全局状态的聚合视图做出准入决定,而无需在请求执行路径上进行任何额外的同步通信。 然而,由于共享状态是异步接收的,Impala 守护进程可能会在本地做出导致超出策略指定限制的决策。 实际上,这并没有问题,因为状态通常比非平凡查询更新得更快。此外,准入控制机制主要被设计为一种简单的节流机制,而不是像 YARN 这样的资源管理解决方案。
资源池是分层定义的。传入的请求根据放置策略分配给资源池,并且可以使用 ACL 控制对资源池的访问。 配置使用 YARN 公平调度器分配文件和 Llama 配置指定,Cloudera Manager 提供简单的用户界面来配置资源池,无需重新启动任何正在运行的服务即可对其进行修改。
7 评估
本节的目的不是详尽地评估 Impala 的性能,而主要是给出一些指示。有独立的学术研究得出了类似的结论,例如 [6]。
7.1 搭建实验环境
所有实验都在同一个 21 节点集群上运行。集群中的每个节点都是 2 插槽计算机,具有 2.00GHz 的 6 核 Intel Xeon CPU E5-2630L。 每个节点都有 64GB RAM 和 12 个 932GB 磁盘驱动器(一个用于操作系统,其余用于 HDFS)。
我们在 15TB 比例因子数据集上运行了一个决策支持风格基准测试,该基准测试由 TPC-DS 查询的子集组成。 在下面的结果中,我们根据查询访问的数据量将查询分类为交互式、报告和深度分析查询。 具体来说,交互式存储桶包含查询:q19、q42、q52、q55、q63、q68、q73 和 q98; 报告桶包含查询:q27、q3、q43、q53、q7 和 q89; 深度分析桶包含查询:q34、q46、q59、q79 和 ss max。 我们用于这些测量的套件是公开可用的。
对于我们的比较,我们使用了最流行的 SQL-onHadoop 系统,比如说:Impala、Presto、Shark、SparkSQL 和 Hive 0.13。 由于在除 Impala 之外的所有测试引擎中都缺少基于成本的优化器,我们测试了所有引擎的查询已转换为 SQL-92 样式连接。 为了保持一致性,我们对 Impala 运行了相同的查询,尽管 Impala 在没有这些修改的情况下产生了相同的结果。
每个引擎都根据其表现最佳的文件格式进行评估,同时始终使用 Snappy 压缩来确保公平比较:Apache Parquet 上的 Impala、ORC 上的 Hive 0.13、RCFile 上的 Presto 和 Parquet 上的 SparkSQL。
7.2 单用户性能
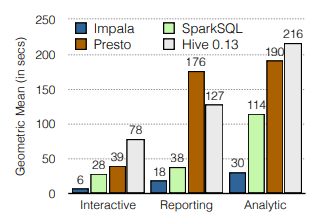
图 6 比较了四个系统在单用户运行时的性能,其中单个用户以零思考时间重复提交查询。在所有查询运行的单用户工作负载上,Impala 的性能优于所有替代方案。 Impala 的性能优势从 2.1 倍到 13.0 倍不等,平均快 6.7 倍。实际上,这与早期版本 Impala 的 Hive 0.13(从平均 4.9 倍到 9 倍)和 Presto(从平均 5.3 倍到 7.5 倍)相比,性能优势差距更大。
7.3 多用户性能
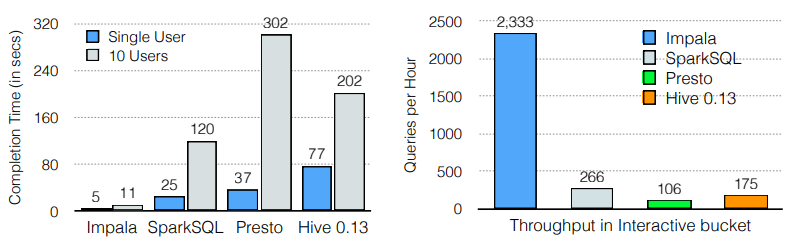
Impala 的卓越性能在多用户工作负载中变得更加明显,这在现实世界的应用程序中无处不在。图 7(左) 显示了当有 10 个并发用户从交互式类别提交查询时四个系统的响应时间。 在这种情况下,从单用户到并发用户工作负载时,Impala 的性能优于其他系统,从 6.7 倍到 18.7 倍。 根据比较,加速从 10.6 倍到 27.4 倍不等。请注意,Impala 在 10 用户负载下的速度几乎是单用户负载下的一半——而替代方案的平均值仅为单用户负载下的五分之一。
同样,图 7 (右)比较了四个系统的吞吐量。当 10 个用户从交互式存储桶提交查询时,Impala 的吞吐量比其他系统高 8.7 倍至 22 倍。
7.4 与商业 RDBMS 比较
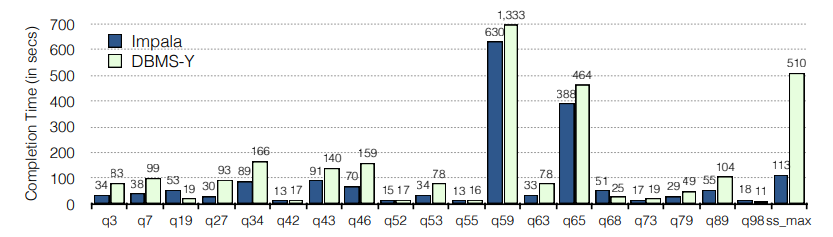
从以上比较可以看出,Impala 在性能方面在 SQL-on Hadoop 系统中处于领先地位。但 Impala 也适合部署在传统的数据仓库设置中。 在图 8 中,我们将 Impala 的性能与流行的商业柱状分析 DBMS 进行了比较,由于有限制性的专有许可协议,此处称为“DBMS-Y”。 我们使用比例因子为 30,000(30TB 原始数据)的 TPC-DS 数据集,并根据前面段落中介绍的工作负载运行查询。 我们可以看到 Impala 的性能比 DBMS-Y 高出 4.5 倍,平均高出 2 倍,只有三个查询执行得更慢。
8 路线图
在本文中,我们概述了 Cloudera Impala。 尽管 Impala 已经对现代数据管理产生了影响,并且是 SQL-on-Hadoop 系统中的性能领导者,但仍有许多工作要做。 我们的路线图项目大致分为两类:添加更传统的并行 DBMS 技术,这是为了解决越来越多的现有数据仓库工作负载所必需的,以及解决 Hadoop 环境所特有的问题的解决方案。
8.1 额外的 SQL 支持
Impala 对 SQL 的支持在 2.0 版本中已经相当完善了,但是仍然缺少一些标准的语言特性:set MINUS 和 INTERSECT;ROLLUP 和 GROUPING 集;动态分区修剪;日期/时间/日期时间数据类型。 我们计划在下一个版本中添加这些内容。
Impala 目前仅限于平面关系模式,虽然这通常足以满足预先存在的数据仓库工作负载,但我们看到更多使用更新的文件格式,这些格式允许本质上是嵌套关系模式,并添加了复杂的列类型(结构 ,数组,地图)。 Impala 将被扩展为以对嵌套级别或可以在单个查询中处理的嵌套元素的数量没有限制的方式处理这些模式。
8.2 其他性能增强
计划中的性能增强包括连接、聚合和排序的节点内并行化,以及更普遍地使用运行时代码生成来完成诸如网络传输的数据准备、查询输出的具体化等任务。
我们还考虑将在查询处理期间需要物化的数据切换到列式规范内存格式,以便利用 SIMD 指令 [11, 13]。
另一个计划改进的领域是 Impala 的查询优化器。 它探索的计划空间目前被故意限制健壮性/可预测性,部分原因是缺乏复杂的数据统计信息(例如直方图)和额外的模式信息(例如主/外键约束、列的可空性),这些信息可以实现更准确的成本计算生成计划替代方案。 我们计划在近期内将直方图添加到表/分区元数据中,以纠正其中的一些问题。利用这些额外的元数据并以稳健的方式合并复杂的计划重写是一项具有挑战性的持续任务。
8.3 元数据和统计收集
在 Hadoop 环境中收集元数据和表统计信息很复杂,因为与 RDBMS 不同,新数据可以通过将数据文件移动到表的根目录中简单地显示出来。 目前,用户必须发出命令来重新计算统计数据并更新物理元数据以包含新的数据文件,但这已经证明是有问题的:用户经常忘记发出该命令,或者在确切需要发出该命令时感到困惑。 该问题的解决方案是通过运行后台进程自动检测新数据文件,该进程还更新元数据并安排计算增量表统计信息的查询。
8.4 自动数据转换
允许并排使用多种数据格式的更具挑战性的方面之一是从一种格式转换为另一种格式。数据通常以结构化的面向行的格式(例如 Json、Avro 或 XML)或作为文本添加到系统中。 另一方面,从性能的角度来看,Parquet 等面向列的格式是理想的。在生产环境中,让用户管理从一个到另一个的转换通常是一项不平凡的任务:它本质上需要建立一个可靠的数据管道(识别新数据文件,在转换过程中合并它们等),这本身就需要大量的工程。 我们正计划增加转换过程的自动化,以便用户可以标记表进行自动转换;转换过程本身依赖于后台元数据和统计数据收集过程,该过程另外安排在新数据文件上运行的转换查询。
8.5 资源管理
开放多租户环境中的资源管理,其中 Impala 与其他处理框架(如 MapReduce、Spark 等)共享集群资源,目前仍是一个未解决的问题。 与 YARN 的现有集成目前并未涵盖所有用例,并且 YARN 专注于拥有具有同步资源预留的单个预留注册表,这使得难以适应低延迟、高吞吐量的工作负载。我们正在积极研究这个问题的新解决方案。
8.6 支持远程数据存储
Impala 目前依靠存储和计算的搭配来实现高性能。然而,像亚马逊的 S3 这样的云数据存储正变得越来越流行。 此外,基于 SAN 的传统存储基础架构需要将计算和存储分离。我们正在积极致力于扩展 Impala 以访问 Amazon S3(计划用于 2.2 版)和基于 SAN 的系统。 除了简单地将本地存储替换为远程存储之外,我们还计划研究允许本地处理而不增加额外操作负担的自动缓存策略。
9 结论
在本文中,我们介绍了 Cloudera Impala,这是一个开源 SQL 引擎,旨在将并行 DBMS 技术引入 Hadoop 环境。 我们的性能结果表明,尽管 Hadoop 起源于批处理环境,但可以在其上构建一个分析 DBMS,其性能与当前的商业解决方案一样好或更好,但同时保留了灵活性和成本效益的 Hadoop。
在目前的状态下,Impala 已经可以取代传统的、单一的分析 RDBMS 来处理许多工作负载。 我们预测,这些系统在 SQL 功能方面的差距将随着时间的推移而消失,并且 Impala 将能够承担越来越多的现有数据仓库工作负载。 然而,我们相信 Hadoop 环境的模块化特性(其中 Impala 利用了跨平台共享的许多标准组件)带来了一些传统的单体 RDBMS 无法复制的优势。 特别是,混合文件格式和处理框架的能力意味着单个系统可以处理更广泛的计算任务,而无需数据移动,这本身通常是组织使用数据做某事的最大障碍之一。
Hadoop 生态系统中的数据管理仍然缺乏过去几十年为商业 RDBMS 开发的一些功能; 尽管如此,我们预计这种差距会迅速缩小,并且开放模块化环境的优势将使其在不久的将来成为主导的数据管理架构。
参考资料
[1] A. Ailamaki, D. J. DeWitt, M. D. Hill, and M. Skounakis. Weaving relations for cache performance. In VLDB,2001.
[2] Apache. Centralized cache management in HDFS. Available at https://hadoop.apache.org/docs/r2.3.0/hadoopproject-dist/hadoop-hdfs/CentralizedCacheManagement.html.
[3] Apache. HDFS short-circuit local reads. Available at http://hadoop.apache.org/docs/r2.5.1/hadoop-projectdist/hadoop-hdfs/ShortCircuitLocalReads.html.
[4] Apache. Sentry. Available at http://sentry.incubator.apache.org/.
[5] P. Flajolet, E. Fusy, O. Gandouet, and F. Meunier. HyperLogLog: The analysis of a near-optimal cardinality estimation algorithm. In AOFA, 2007.
[6] A. Floratou, U. F. Minhas, and F. Ozcan. SQL-onHadoop: Full circle back to shared-nothing database architectures. PVLDB, 2014.
[7] G. Graefe. Encapsulation of parallelism in the Volcano query processing system. In SIGMOD, 1990.
[8] C. Lattner and V. Adve. LLVM: A compilation framework for lifelong program analysis & transformation. In CGO, 2004.
[9] S. Melnik, A. Gubarev, J. J. Long, G. Romer, S. Shivakumar, M. Tolton, and T. Vassilakis. Dremel: Interactive analysis of web-scale datasets. PVLDB, 2010.
[10] S. Padmanabhan, T. Malkemus, R. C. Agarwal, and A. Jhingran. Block oriented processing of relational database operations in modern computer architectures. In ICDE, 2001.
[11] V. Raman, G. Attaluri, R. Barber, N. Chainani, D. Kalmuk, V. KulandaiSamy, J. Leenstra, S. Lightstone, S. Liu, G. M. Lohman, T. Malkemus, R. Mueller, I. Pandis, B. Schiefer, D. Sharpe, R. Sidle, A. Storm, and L. Zhang. DB2 with BLU Acceleration: So much more than just a column store. PVLDB, 6, 2013.
[12] V. K. Vavilapalli, A. C. Murthy, C. Douglas, S. Agarwal, M. Konar, R. Evans, T. Graves, J. Lowe, H. Shah, S. Seth, B. Saha, C. Curino, O. O’Malley, S. Radia, B. Reed, and E. Baldeschwieler. Apache Hadoop YARN: Yet another resource negotiator. In SOCC, 2013.
[13] T. Willhalm, N. Popovici, Y. Boshmaf, H. Plattner, A. Zeier, and J. Schaffner. SIMD-scan: ultra fast inmemory table scan using on-chip vector processing units. PVLDB, 2, 2009.