Flink 执行环境
Flink 执行环境
简介
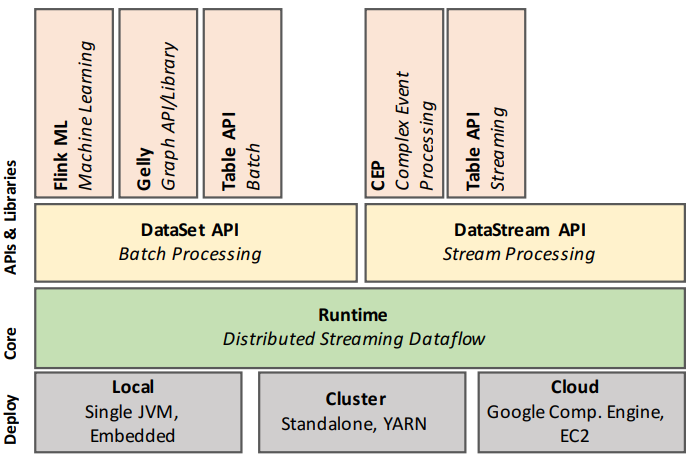
在 Flink 架构中有两个核心 API:用于处理有限数据集(通常称为批处理)的 DataSet API,以及用于处理潜在无界数据流(通常称为流处理)的 DataStream API。
DataStream API
在 Flink 源码中是这样描述:
StreamExecutionEnvironment 是执行流程序的上下文。
LocalStreamEnvironment 将导致在当前 JVM 中执行,RemoteStreamEnvironment 将导致在远程设置上执行。
该环境提供了控制作业执行(例如设置并行度或容错/检查点参数)以及与外部世界交互(访问数据)的方法。
相关类如下:
- LocalStreamEnvironment 本地模式执行
- RemoteStreamEnvironment 提交到远程集群执行
- StreamPlanEnvironment 执行计划
在编写流处理程序时可以使用如下代码创建执行环境:
1 | |
注:由于 DataSet API 被弃用,所以在使用 DataStream API 运行批处理时需要额外配置运行参数
execution.runtime-mode=BATCH(为了保持灵活建议在运行时指定此参数)。
使用 DataStream API 程序由以下几部分构成:
- 获取执行环境
- 载入或创建初始化数据
- 声明数据的转化方式
- 声明数据的存储位置
- 触发程序执行
Table API
Table API 是构建在 Stream API 和 DataSet API 之上的 API。该 API 的核心概念是 Table 用作查询的输入和输出。
在 Flink 源码中是这样描述:
TabelEnvironment 是用于创建表和 SQL API 程序的基类、入口和核心上下文。
在编写流处理程序时可以使用如下代码创建执行环境:
1 | |
或者可以从 StreamExecutionEnvironment 进行创建:
1 | |
DataSet API
注:DataSet API 在 Flink 1.12 之后已经被 软弃用,不建议使用此 API。
在 Flink 源码中是这样描述:
ExecutionEnvironment 是执行程序的上下文。LocalEnvironment 将导致在当前 JVM 中执行,RemoteEnvironment 将导致在远程设置上执行。
该环境提供了控制作业执行(例如设置并行度)和与外界交互(访问数据)的方法。
请注意,执行环境需要强类型信息,用于所有执行的操作的输入和返回类型。这意味着环境需要知道操作的返回值是例如字符串和整数的元组。因为 Java 编译器丢弃了大部分泛型类型信息,所以大多数方法都尝试使用反射重新获取该信息。在某些情况下,可能需要手动将该信息提供给某些方法。
相关类如下:
- LocalEnvironment 本地模式执行
- RemoteEnvironment 提交到远程集群执行
- CollectionEnvironment 集合数据集模式执行
- OptimizerPlanEnvironment 不执行作业,仅创建优化的计划
- PreviewPlanEnvironment 提取预先优化的执行计划
在编写批处理程序时可以使用如下代码创建执行环境:
1 | |