Apache Hive: From MapReduce to Enterprise-grade Big Data Warehousing 中文翻译
Apache Hive: From MapReduce to Enterprise-grade Big Data Warehousing 中文翻译
作者:Jesús Camacho-Rodríguez, Ashutosh Chauhan, Alan Gates, Eugene Koifman, Owen O’Malley, Vineet Garg, Zoltan Haindrich, Sergey Shelukhin, Prasanth Jayachandran, Siddharth Seth, Deepak Jaiswal, Slim Bouguerra, Nishant Bangarwa, Sankar Hariappan, Anishek Agarwal, Jason Dere, Daniel Dai, Thejas Nair, Nita Dembla, Gopal Vijayaraghavan, Günther Hagleitner
摘要
Apache Hive 是一个用于分析大数据工作负载的开源关系型数据库。本文中,我们描述了从批处理工具到成熟的企业数据仓库系统的关键创新。 我们提出了一种混合架构,它将传统的 MPP 技术与最新的大数据和云概念相结合,以实现当今分析应用程序所需的规模和性能。 我们通过沿四个主轴详细说明增强功能来探索系统:事务、优化器、运行时(runtime)和联邦集群(federation)。然后,我们提供实验结果来展示系统在典型工作负载下的性能,并以查看社区路线图作为总结。
1. 简介
10 多年前首次引入 Hive 时 [55],作者的动机是在 Hadoop MapReduce 之上公开一个类似 SQL 的接口,以将用户从处理并行批处理作业的低级实现细节中抽象出来。
Hive 主要专注于 ExtractTransform-Load (ETL) 或批处理报告工作负载,这些工作负载包括 (i) 读取大量数据,(ii) 对该数据执行转换(例如,数据整理、整合、聚合)以及最后 (iii) 加载(输出)到其他系统用于进一步分析。
随着 Hadoop 成为使用 HDFS 进行廉价数据存储的无处不在的平台,开发人员专注于增加可以在平台内高效执行的工作负载范围。
在 Hadoop 引入 YARN [56] 资源管理框架之后不久 Spark [14,59] 或 Flink [5,26] 等 MapReduce 之外的数据处理引擎也可以在支持 YARN 之后直接在 Hadoop 上运行。
用户也越来越关注将他们的数据仓库工作负载从其他系统迁移到 Hadoop。这些工作负载包括交互式和临时报告、仪表板和其他商业智能用例。
有一个共同要求使这些工作负载对 Hadoop 构成挑战:它们需要低延迟 SQL 引擎。实现这一目标的多项努力是并行启动的,并且出现了与 YARN 兼容的新 SQL MPP 系统,例如 Impala [8, 42] 和 Presto [48]。
Hive 社区没有实施新系统,而是得出结论,该项目的当前实施为支持这些工作负载提供了良好的基础。 Hive 是为 Hadoop 中的大规模可靠计算而设计的,它已经提供了 SQL 兼容性(只有一部分)和与其他数据管理系统的连接。 然而,Hive 需要发展并进行重大改造,采用多年来广泛研究的通用数据仓库技术以满足这些新用例的要求。
以前向研究界展示的关于 Hive 的工作主要集中在 (i) 它在 HDFS 和 MapReduce [55] 之上的初始架构和实现,以及 (ii) 改进以解决原始系统中的多个性能缺点,包括引入优化的列文件格式,物理优化以减少查询计划中 MapReduce 阶段的数量,以及矢量化执行模型以提高运行时效率 [39]。
相反,本文描述了在上一篇文章发表之后在 Hive 中引入的重要创新。特别是,它侧重于沿四个不同主轴改进系统的相关工作:
SQL 和 ACID 支持(第 3 节) SQL 合规性是数据仓库的一项关键要求。因此,Hive 中的 SQL 支持得到了扩展,包括相关的子查询、完整性约束和扩展的 OLAP 操作等。 反过来,仓库用户需要支持来按需插入、更新、删除和合并他们的个人记录。Hive 使用构建在 Hive Metastore 之上的事务管理器通过快照隔离策略来提供 ACID 保证。
优化技术(第 4 节) 查询优化与使用声明性查询语言(如 SQL)的数据管理系统尤其相关。Hive 没有从头开始实现自己的优化器,而是选择与 Calcite [3, 19] 集成,并将其优化功能带入系统。
此外,Hive 还包括数据仓库环境中常用的其他优化技术,例如查询重新优化、查询结果缓存和物化视图重写。
运行时的延迟(第 5 节) 为了涵盖更广泛的用例,包括交互式查询,改善延迟至关重要。Hive 支持优化的列数据存储方式和运算符的矢量化在之前的文章中已经描述过了 [39]。
除了这些改进之外,Hive 已经从 MapReduce 转移到 Tez [15, 50],这是一个与 YARN 兼容的运行时,它比 MapReduce 提供了更多的灵活性来实现任意数据处理应用程序。
此外,Hive 包括 LLAP,这是一个额外的持久性长期运行的执行程序层,可提供数据缓存、设施运行时优化,并避免启动时的 YARN 容器分配开销。
联邦集群性能(第 6 节) Hive 最重要的特性之一是能够在过去几年出现的许多专业数据管理系统之上提供统一的 SQL 层。 由于其 Calcite 集成和存储处理程序的改进,Hive 可以无缝地推送计算并从这些系统读取数据。反过来,该实现很容易扩展以支持将来的其他系统。
本文的其余部分安排如下。第 2 节提供了 Hive 架构和主要组件的背景。第 3-6 节描述了我们对沿上述主轴改进系统的主要贡献。第 7 节介绍了 Hive 的实验评估。 第 8 节讨论了新功能的影响,而第 9 节简要介绍了项目的路线图。最后,第 10 节总结了我们的结论。
2 系统架构
在本节中,我们将简要介绍 Hive 的架构。图 1 描述了系统中的主要组件。
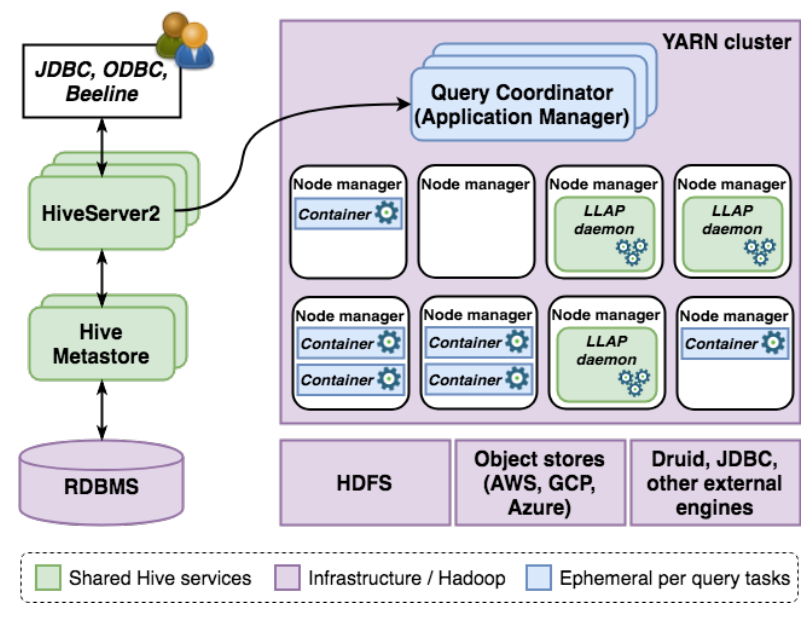
数据存储 Hive 中的数据可以使用任何支持的文件格式存储在与 Hadoop 兼容的任何文件系统中。
截至今天,最常见的文件格式是 ORC [10] 和 Parquet [11]。反过来,兼容的文件系统包括最常用的分布式文件系统实现 HDFS,以及所有主要的商业云对象存储,如 AWS S3 和 Azure Blob 存储。
此外,Hive 还可以读取和写入数据到其他独立处理系统,例如 Druid [4, 58] 或 HBase [6],我们将在第 6 节中详细讨论。
数据目录 Hive 使用 Hive Metastore(简称 HMS)存储有关其数据源的所有信息。简而言之,HMS 是 Hive 可查询的所有数据的目录。
它使用 RDBMS 来持久化信息,并依赖 Java 对象关系映射实现 DataNucleus [30] 来简化后端对多个 RDBMS 的支持。对于需要低延迟的调用,HMS 可以绕过 DataNucleus 直接查询 RDBMS。
HMS API 支持多种编程语言,该服务使用 Thrift [16] 实现,这是一个提供接口定义语言、代码生成引擎和二进制通信协议实现的软件框架。
可更换的数据处理引擎 Hive 已成为 Hadoop 之上最受欢迎的 SQL 引擎之一,它已逐渐远离 MapReduce,以支持与 YARN [50] 兼容的更灵活的处理运行时。
虽然仍然支持 MapReduce,但目前 Hive 最流行的运行时是 Tez [15, 50]。
Tez 通过将数据处理建模为 DAG 提供比 MapReduce 更大的灵活性,其中顶点表示应用程序逻辑,边表示数据传输,类似于 Dryad [40] 或 Hyracks [22] 等其他系统。
此外,Tez 与第 5 节中介绍的持久执行和缓存层 LLAP 兼容。
查询服务器 HiveServer2(或简称 HS2)允许用户在 Hive 中执行 SQL 查询。HS2 支持本地和远程 JDBC 和 ODBC 连接;Hive 发行版中包括一个名为 Beeline 的 JDBC 简易客户端。
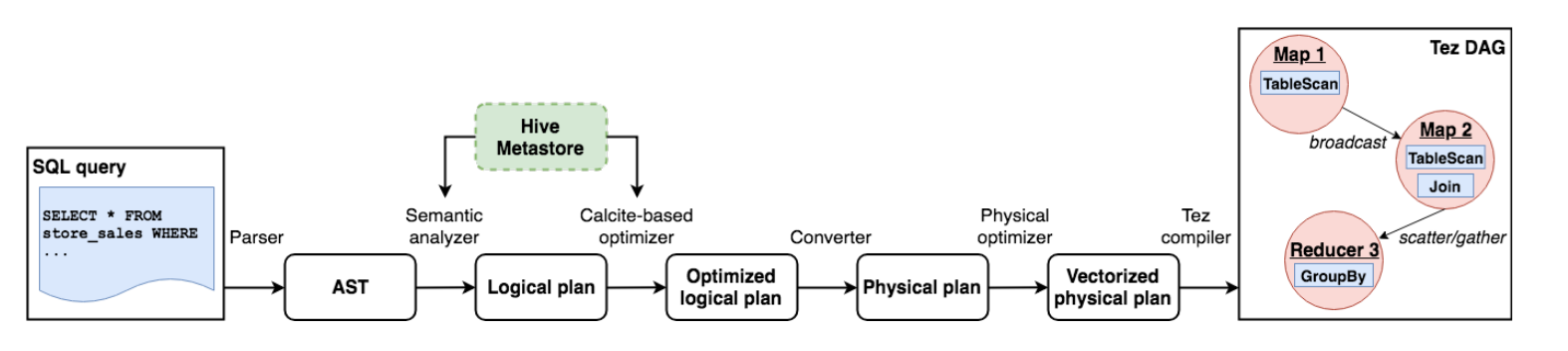
图 2 描述了 SQL 查询在 HS2 中经过的各个阶段,以成为可执行计划。一旦用户向 HS2 提交查询,该查询由驱动程序处理,驱动程序解析语句并从其 AST 生成 Calcite [3, 19] 逻辑计划。
然后优化 Calcite 计划。请注意,HS2 访问有关 HMS 中数据源的信息以进行验证和优化。随后,计划被转换为物理计划,可能会引入额外的操作符用于数据分区、排序等。
HS2 对物理计划 DAG 执行额外的优化,如果支持计划中的所有运算符和表达式,则可以从中生成矢量化计划 [39]。
物理计划被传递给任务编译器,它将操作符树分解为可执行任务的 DAG。Hive 为每个支持的处理运行时实现了一个单独的任务编译器,即 Tez、Spark 和 MapReduce。
生成任务后,驱动程序将它们提交给 YARN 中的运行时应用程序管理器,由其处理执行。对于每个任务,首先初始化该任务中的物理操作符,然后它们以流水线方式处理输入数据。
执行完成后,驱动程序获取查询结果并将其返回给用户。
3 SQL 和 ACID 支持
标准 SQL 和 ACID 事务是企业数据仓库中的关键要求。在本节中,我们将介绍 Hive 更广泛的 SQL 支持。 此外,我们描述了对 Hive 所做的改进,以便在 Hadoop 之上提供 ACID 保证。
3.1 SQL 支持
为了替代传统数据仓库,需要扩展 Hive 以支持标准 SQL 的更多功能。Hive 使用嵌套数据模型,支持所有主要的原子 SQL 数据类型以及非原子类型,例如 STRUCT、ARRAY 和 MAP。 此外,每个新的 Hive 版本都增加了对作为 SQL 规范一部分的重要构造的支持。 例如,扩展了对相关子查询的支持,即引用外部查询列的子查询、高级 OLAP 操作(如分组或窗口函数)、集合操作和完整性约束等。 另一方面,Hive 保留了其原始查询语言的多个功能,这些功能对其用户群很有价值。最流行的功能之一是能够在创建表时使用 PARTITIONED BY 列子句指定物理存储布局。 简而言之,该子句允许用户对表进行水平分区。然后 Hive 将每组分区值的数据存储在文件系统的不同目录中。为了说明这个想法,请考虑下表定义和图 3 中描述的相应物理布局:

1 | |
使用 PARTITIONED BY 子句的优点是 Hive 将能够轻松跳过扫描完整分区以查找过滤这些值的查询。
3.2 ACID 支持
最初,Hive 仅支持从表中插入和删除完整分区 [55]。尽管对于 ETL 工作负载来说缺乏行级操作是可以接受的,但随着 Hive 演变为支持许多传统的数据仓库工作负载,对完全 DML 支持和 ACID 事务的需求越来越大。
因此,Hive 现在支持执行 INSERT、UPDATE、DELETE 和 MERGE 语句。
它通过 Snapshot Isolation [24] 为读取和定义明确的语义提供 ACID 保证,以防使用构建在 HMS 之上的事务管理器发生故障。
目前事务只能跨越一个语句; 我们计划在不久的将来支持多语句事务。但是,可以使用 Hive 多插入语句 [55] 在单个事务中写入多个表。
在 Hive 中支持行级操作需要克服的主要挑战是 (i) 系统中缺少事务管理器,以及 (ii) 底层文件系统中缺少文件更新支持。在下文中,我们提供了有关在 Hive 中实施 ACID 以及如何解决这些问题的更多详细信息。
事务和锁管理 Hive 在 HMS 中存储事务和锁定信息状态。它为系统中运行的每个事务使用全局事务标识符或 TxnId,即 Metastore 生成的单调递增值。 反过来,每个 TxnId 映射到一个或多个写入标识符或 WriteId。WriteId 也是由 Metastore 生成的单调递增值,但在表范围内。 WriteId 与事务写入的每条记录一起存储;同一个事务写入同一个表的所有记录共享同一个 WriteId。 反过来,共享相同 WriteId 的文件使用 FileId 唯一标识,而文件中的每条记录由 RowId 字段唯一标识。 请注意,WriteId、FileId 和 RowId 的组合唯一标识了表中的每条记录。Hive 中的删除操作被建模为标记记录的插入,该记录指向被删除记录的唯一标识符。
为了实现快照隔离,HS2 在执行查询时获取需要读取的数据的逻辑快照。快照由一个事务列表表示,该列表包含当时分配的最高 TxnId,即高水位线,以及它下面的一组打开和中止的事务。 对于查询需要读取的每张表,HS2 首先通过联系 HMS 从事务列表中生成 WriteId 列表; WriteId 列表类似于事务列表,但在单个表的范围内。 计划中的每个扫描操作在编译期间都绑定到一个 WriteId 列表。该扫描中的读取器将跳过 WriteId (i) 高于高水位线或 (ii) 是打开和中止事务集的一部分的行。 保留全局和每个表标识符的原因是每个表的读取器保持较小的状态,当系统中有大量打开的事务时,这对性能至关重要。
对于分区表,锁定粒度是分区,而对于未分区表,需要锁定全表。HS2 只需要为破坏读写器的操作获取排他锁,例如 DROP PARTITION 或 DROP TABLE 语句。 所有其他常见操作只是获取共享锁。更新和删除通过跟踪其写入集并在提交时解决冲突来使用乐观冲突解决,让第一次提交获胜。
数据和文件布局 Hive 将每个表和分区的数据存储在不同的目录中(回忆图 3)。
与 [45] 类似,我们在每个表或分区中使用不同的存储或目录来支持并发读写操作:base 和 delta,它们又可能包含一个或多个文件。
基本存储中的文件包含直到某个 WriteId 的所有有效记录。例如,文件夹 base_100 包含直到 WriteId 100 的所有记录。另一方面,增量目录包含具有 WriteId 范围内的记录的文件。
Hive 为插入和删除的记录保留单独的增量目录;更新操作分为删除和插入操作。插入或删除事务创建一个增量目录,其中记录绑定到单个 WriteId,例如 delta_101_101 或 delete_delta_102_102。
包含多个 WriteId 的增量目录是作为压缩过程的一部分创建的(如下所述)。
如前所述,查询中的表扫描具有与之关联的 WriteId 列表。扫描中的读取器丢弃完整目录以及基于当前快照无效的单个记录。 当增量文件中存在删除时,基本和插入增量文件中的记录需要与适用于其 WriteId 范围的删除增量反连接。 由于删除记录的增量文件通常很小,因此它们可以大部分时间保存在内存中,从而加速合并阶段。
数据压缩(compaction) 压缩是 Hive 中的过程,它将 delta 目录中的文件与 delta 目录中的其他文件合并(称为次要压缩),或者将 delta 目录中的文件与基本目录中的文件合并(称为主要压缩)。 定期运行压缩的关键原因是(i) 减少表中目录和文件的数量,否则会影响文件系统性能,(ii)减少读取端在查询执行时合并文件的工作量,以及 (iii) 缩短与每个快照关联的打开和中止 TxnId 和 WriteId 的集合,即主要压缩删除历史记录,增加已知表中所有记录有效的 TxnId。
当超过某些阈值时,HS2 会自动触发压缩,例如,表中的 delta 文件数或 delta 文件中的记录与基本文件的比率。最后,请注意,压缩不需要对表进行任何锁定。 实际上,清理阶段与合并阶段是分开的,因此任何正在进行的查询都可以在文件从系统中删除之前完成其执行。
4 查询优化
虽然在 Hive 的初始版本中对优化的支持是有限的,但显然其执行内部的开发不足以保证高效的性能。因此,目前该项目包括关系数据库系统中通常使用的许多复杂技术。 本节介绍最重要的优化功能,这些功能可帮助系统生成更好的计划并改进查询执行,包括它与 Apache Calcite 的基本集成。
4.1 基于规则和成本的优化器
最初,Apache Hive 在解析输入 SQL 语句时执行了多次重写以提高性能。此外,它包含一个基于规则的优化器,该优化器将简单的转换应用于查询生成的物理计划。 例如,许多优化的目标是尽量减少数据混洗的成本,这是 MapReduce 引擎中的一项关键操作。还有其他优化来下推过滤器谓词、投影未使用的列和修剪分区。 虽然这对某些查询很有效,但使用物理计划表示使得实现复杂的重写(例如连接重新排序、谓词简化和传播,或基于物化视图的重写)变得过于复杂。
因此,引入了由 Apache Calcite [3, 19] 提供支持的新计划表示和优化器。
Calcite 是一个模块化和可扩展的查询优化器,具有内置元素,可以以不同的方式组合以构建您自己的优化逻辑。其中包括不同的重写规则(rewriting rules)、计划者(planner)和成本模型(cost model)。
Calcite 提供了两种不同的规划器引擎:(i) 基于成本的规划器,它触发重写规则以降低整体表达式成本,以及 (ii) 穷举计划器,它穷举地触发规则,直到它生成不再被任何规则修改。转换规则对这两个规划引擎都不起作用。
Hive 实现类似于其他查询优化器 [52] 的多阶段优化,其中每个优化阶段使用一个计划器和一组重写规则。这允许 Hive 通过指导搜索不同的查询计划来减少整体优化时间。
Apache Hive 中启用的一些 Calcite 规则是连接重新排序、多个运算符重新排序和消除、常量折叠和传播以及基于约束的转换。
统计数据 表统计信息存储在 HMS 中,并在计划时提供给 Calcite。这些包括表基数、不同值的数量、每列的最小值和最大值。
存储统计信息以便它们可以以附加方式组合,即未来插入以及跨多个分区的数据可以添加到现有统计信息中。范围和基数可以简单地合并。
对于不同值的数量,HMS 使用基于 HyperLogLog++ [38] 的位数组表示,可以在不损失近似精度的情况下进行组合。
4.2 查询重新优化
当执行期间抛出某些错误时,Hive 支持查询重新优化。特别是,它实现了两个独立的重新优化策略。
第一个策略,覆盖,更改所有查询重新执行的某些配置参数。例如,用户可以选择强制查询重新执行中的所有连接使用某种算法,例如,带有排序合并的哈希分区。当已知某些配置值可以使查询执行更加健壮时,这可能很有用。
第二种策略,重新优化,依赖于运行时捕获的统计信息。在计划查询时,优化器会根据从 HMS 检索到的统计信息来估计计划中中间结果的大小。如果这些估计不准确,优化器可能会犯计划错误,例如错误的连接算法选择或内存分配。 这反过来可能导致性能不佳和执行错误。Hive 为计划中的每个运算符捕获运行时统计信息。如果在查询执行期间检测到任何上述问题,则使用运行时统计信息重新优化查询并再次执行。
4.3 查询结果缓存
仓库的事务一致性允许 Hive 通过使用参与表的内部事务状态来重用先前执行的查询的结果。在处理生成重复相同查询的 BI 工具时,查询缓存提供了可扩展性优势。
每个 HS2 实例都保留自己的查询缓存组件,该组件又保留从查询 AST 表示到条目的映射,该条目包含结果位置和回答查询的数据快照的信息。该组件还负责清除过时的条目并清理这些条目使用的资源。
在查询编译期间,HS2 在初步步骤中使用输入查询 AST 检查其缓存。查询中不合格的表引用在 AST 用于证明缓存之前被解析,因为根据查询执行时的当前数据库,具有相同文本的两个查询可能访问来自不同数据库的表。 如果缓存命中并且查询使用的表不包含新的或修改的数据,则查询计划将包含从缓存位置获取结果的单个任务。 如果该条目不存在,则查询照常运行,如果查询满足某些条件,则为查询生成的结果保存到缓存中;例如,查询不能包含非确定性函数(rand)、运行时常量函数(current_date、current_timestamp)等。
查询缓存有一个挂起的条目模式,当数据更新并且其中几个同时观察到缓存未命中时,它可以防止雷鸣般的相同查询群。 缓存将被第一个进入的查询重新填充。此外,该查询可能会获得更多的集群容量,因为它会将结果提供给所有其他遭受缓存未命中的并发相同查询。
4.4 物化视图与重写
传统上,用于加速数据仓库中查询处理的最强大的技术之一是相关物化视图的预计算 [28,31,35-37]。
1 | |
图 4:物化视图定义 (a) 和完整样本 (b) 和部分样本 © 包含重写。
Apache Hive 支持物化视图和基于这些物化的自动查询重写。特别的是,物化视图只是语义丰富的表。因此,它们可以由 Hive 或其他支持的系统本地存储(参见第 6 节),并且它们可以无缝利用 LLAP 加速等功能(参见第 5.1 节)。 优化器依靠 Calcite 自动生成对 SelectProject-Join-Aggregate (SPJA)查询表达式的全部和部分包含的重写(参见图 4)。 重写算法利用 Hive 中声明的完整性约束信息,例如主键、外键、唯一键和非空值,以产生额外的有效转换。该算法封装在规则中,由基于成本的优化器触发,该优化器负责决定是否应该使用重写来回答查询。 请注意,如果多次重写适用于查询的不同部分,优化器最终可能会选择多个视图替换。
物化视图维护 当物化视图使用的源表中的数据发生更改时,例如,插入新数据或修改现有数据,我们将需要刷新物化视图的内容以使其与这些更改保持同步。 目前,物化视图的重建操作需要由用户使用 REBUILD 语句手动触发。
默认情况下,Hive 尝试增量重建物化视图 [32, 34],如果失败,则回退到完全重建。
当前实现仅在对源表进行 INSERT 操作时支持增量重建,而 UPDATE 和 DELETE 操作将强制物化视图的完全重建。
一个有趣的方面是增量维护依赖于重写算法本身。由于查询与数据的快照相关联,因此物化视图定义通过扫描每个表的 WriteId 列值的过滤条件来丰富(参见第 3.2 节)。 这些过滤条件反映了创建或最后刷新实体化视图时的数据快照。当触发维护操作时,重写算法可能会产生部分包含的重写,该重写从源表中读取物化视图和新数据。 这个重写的计划又被转换为 (i) 如果它是 SPJ 物化视图,则为 INSERT 操作,或者 (ii) 如果它是 SPJA 物化视图,则为 MERGE 操作。
物化视图生命周期 默认情况下,一旦物化视图内容过时,物化视图将不会用于查询重写。
但是,在某些情况下,在以微批次更新物化视图的同时接受对陈旧数据的重写可能会很好。 对于这些情况,Hive 允许用户组合定期运行的重建操作,例如每 5/10 分钟一次,并使用表属性定义物化视图定义中允许的数据陈旧窗口。
注:表属性允许 Hive 中的用户使用元数据键值对标记表和物化视图定义
4.5 共享工作优化
Hive 能够识别给定查询的执行计划中的重叠子表达式,只计算一次并重用它们的结果。
共享工作优化器不会触发转换以在计划中找到等效的子表达式,而是仅合并计划的相等部分,类似于先前工作中提出的其他基于重用的方法 [25, 41]。
它在执行之前应用重用算法:它开始合并相同表上的扫描操作,然后继续合并计划运算符,直到发现差异。来自合并表达式的新共享边的数据传输策略的决定留给底层引擎,即 Apache Tez。
基于重用的方法的优点是它可以加速执行多次计算相同子表达式的查询,而不会引入太多优化开销。尽管如此,由于共享工作优化器没有探索等效计划的完整搜索空间,Hive 可能无法检测到现有的重用机会。
4.6 动态半连接(semijoin)缩减
半连接缩减是一种传统技术,用于在查询执行期间减少中间结果的大小 [17, 20]。该优化对于具有一个或多个维度表的星型数据库特别有用。
对这些数据库的查询通常会连接事实表和维度表,这些表使用一个或多个列上的谓词进行过滤。但是,这些列并未在连接条件中使用,因此无法静态创建对事实表的过滤器。
以下 SQL 查询显示了 store_sales 和 store_returns 事实表与商品维度表之间的这种连接示例:
1 | |
通过应用半连接缩减,Hive 评估被过滤的子表达式(在上面的示例中,项目表上的过滤器),随后,表达式产生的值用于跳过从其余表中读取记录。 半连接缩减由优化器引入,并被推送到计划中的扫描运算符中。根据数据布局,Hive 实现了两种优化变体。
动态分区修剪 如果表会被半链接缩减并且被目标链接列分组的话就会应用它。评估过滤子表达式后,Hive 使用生成的值在查询运行时动态跳过读取不需要的分区。 回想一下,每个表分区值都存储在文件系统中的不同文件夹中,因此跳过它们很简单。
索引半连接 如果表被半链接缩减但没有被目标链接列分组的话,Hive 可以使用过滤子表达式生成的值来 (i) 创建具有最小值和最大值的范围过滤条件,(ii) 使用子表达式产生的值创建一个布隆过滤器。
Hive 使用这两个过滤器填充半连接缩减器,这可用于避免在运行时扫描整个行组,例如,如果数据存储在 ORC 文件中 [39]。
5 执行查询
查询执行内部的改进,例如从 MapReduce 到 Apache Tez [50] 的转换以及基于列的存储格式和矢量化运算符 [39] 的实现,将 Hive 中的查询延迟降低了几个数量级。
但是,为了进一步改进执行运行时,Hive 需要额外的增强功能来克服其针对长时间运行的查询量身定制的初始架构固有的限制。
其中,(i) 执行需要在启动时分配 YARN 容器,这很快成为低延迟查询的关键瓶颈,(ii) JustIn-Time (JIT) 编译器优化没有预想中有效,因为容器在查询执行后被简单地杀死,(iii) Hive 无法利用查询内部和查询之间的数据共享和缓存可能性,导致不必要的 IO 开销。
5.1 LLAP: Live Long and Process
Live Long and Process,也称为 LLAP,是一个可选层,它提供持久的多线程查询执行器和内存缓存中的多租户,以在 Hive 中大规模提供更快的 SQL 处理。 LLAP 不会取代 Hive 使用的现有执行运行时,例如 Tez,而是对其进行了增强。特别是,Hive 查询协调器在 LLAP 节点和常规容器上透明地调度和监控执行。
LLAP 的数据 I/O、缓存和查询片段执行能力被封装在守护进程中。守护进程设置为在集群的工作节点中连续运行,促进 JIT 优化,同时避免任何启动开销。 YARN 用于粗粒度的资源分配和调度。它为守护进程保留内存和 CPU 并处理重启和重定位。 守护进程是无状态的:每个都包含许多执行程序以并行运行多个查询片段和一个本地工作队列。 故障和恢复很简单,因为如果 LLAP 守护程序失败,任何节点仍可用于处理输入数据的任何片段。
I/O 调度算法 守护进程使用单独的线程来卸载数据 I/O 和解压缩,我们将其称为 I/O 调度算法。 数据分批读取并转换为内部游程编码 (RLE) 列格式,可用于矢量化处理。一个列批次在读取后立即进入执行阶段,这允许在准备后续批次的同时处理先前的批次。
使用特定于每种格式的插件完成从底层文件格式到 LLAP 内部数据格式的转换。目前 LLAP 支持 ORC [10]、Parquet [11] 和文本文件格式的转译。
I/O 调度算法可以将投影、sargable 谓词和布隆过滤器下推到文件读取器(如果提供的话)。例如,ORC 文件可以利用这些结构跳过读取整个列和行组。
注:sargable 谓词代表如下操作
=, >, <, >=, <=, BETWEEN, LIKE, IS [NOT] NULL
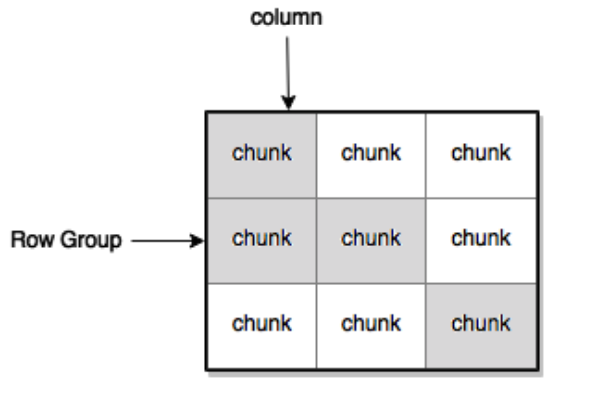
数据缓存 LLAP 将堆外缓存作为其主要缓冲池,用于保存进入 I/O 调度算法的数据。对于每个文件,缓存由 I/O 调度算法沿两个维度寻址:行组和列组。 一组行和列形成一个行列块(参见图 5)。I/O 调度算法重新组装选定的投影并评估谓词以提取块,这些块可以重组为操作员管道的向量批次。在缓存未命中的情况下,在执行重构之前,将用丢失的块重新填充缓存。 结果是当用户沿着非规范化维度导航数据集时缓存的增量填充,这是缓存优化的常见模式。
LLAP 缓存输入文件中的元数据和数据。为了在存在文件更新的情况下保持缓存的有效性,LLAP 使用分配给存储在 HDFS 中的每个文件的唯一标识符以及有关文件长度的信息。 这类似于 blob 存储(如 AWS S3 或 Azure Blob 存储)中的 ETag 字段。
即使对于从未在缓存中的数据,元数据(包括索引信息)也会被缓存。特别是,第一次扫描会批量填充元数据,该元数据用于确定必须加载的行组并在确定缓存未命中之前评估谓词。 这种方法的优点是 LLAP 不会加载对给定查询实际上不必要的块,因此将避免破坏缓存。
缓存是增量可变的,即向表中添加新数据不会导致缓存完全失效。具体来说,缓存仅在查询处理该文件时才获取文件,这会将可见性的控制权转移回查询事务状态。 具体来说,缓存仅在查询处理该文件时才获取文件,这会将可见性的控制权转移回查询事务状态。 由于 ACID 实现通过调整文件级别的可见性来处理事务(回忆第 3.2 节),缓存变成了数据的 MVCC 视图,为可能处于不同事务状态的多个并发查询提供服务。
缓存中数据的驱逐策略是可交换的。目前,默认使用针对具有频繁完整和部分扫描操作的分析工作负载调整的简单 LRFU (最近最少/经常使用)替换策略。 驱逐的数据单位是块。这种选择代表了低开销处理和存储效率之间的折衷。
查询片段执行 LLAP 守护进程执行任意查询计划片段,其中包含过滤器、投影、数据转换、连接、部分聚合和排序等操作。 它们允许并行执行来自不同查询和会话的多个片段。片段中的操作是矢量化的,它们直接在内部 RLE 格式上运行。 对 I/O、缓存和执行使用相同的格式可以最大限度地减少所有这些之间交互所需的工作。
如上所述,LLAP 不包含自己的执行逻辑。相反,它的执行器基本上可以复制 YARN 容器的功能。 但是,出于稳定性和安全性原因,LLAP 仅接受 Hive 代码和静态指定的用户定义函数 (UDF)。
5.2 工作负载管理方面的改进
工作负载管理器控制 Hive 执行的每个查询对 LLAP 资源的访问。管理员可以创建资源计划,即自包含的资源共享配置,以通过在 LLAP 上运行的并发查询来提高执行可预测性和集群共享。 这些因素在多租户环境中至关重要。尽管可以在系统中定义多个资源计划,但在给定时间,对于给定的部署,只有其中一个是活动的。资源计划在 HMS 中由 Hive 持久化。
资源计划包括 (i) 一个或多个资源池,每个池具有最大资源量和并发查询数,(ii) 映射会被当做根,根据特定查询属性(例如用户、组或应用程序)将传入查询到池中,(iii) 根据在运行时收集的查询指标启动操作的触发器,例如终止池中的查询或将查询从一个池移动到另一个池。 尽管查询获得了池中定义的集群资源的保证部分,但工作负载管理器试图防止集群未被充分利用。具体来说,可以为查询分配尚未分配到的池中的空闲资源,直到映射到该池的后续查询声明它们为止。
举个例子,请考虑生产集群的以下资源计划定义:
1 | |
第 1 行为日常创建资源计划。第 2-3 行使用集群中 80% 的 LLAP 资源创建一个池 bi。这些资源可用于同时执行多达 5 个查询。
类似地,第 4-5 行创建了一个池 etl,其中包含可用于同时执行多达 20 个查询的其余资源。第 6-8 行创建一个规则,当查询运行超过 3 秒时,将查询从 bi 移动到 etl 资源池。
注意前面的操作可以执行,因为查询分片比容器更容易抢占。第 9 行为名为 interactive_bi 的应用程序创建了一个映射,即由 interactive_bi 触发的所有查询最初都将从 bi 池中获取资源。
反过来,第 10 行将系统中其余查询的默认池设置为 etl。最后,第 11 行启用并激活集群中的资源计划。
6 联邦集群仓库系统
在过去的十年中,专业数据管理系统 [54] 越来越多,这些系统变得流行,因为它们在特定用例中实现了比传统 RDBMS 更好的成本效益性能。
除了其本机处理能力外,Hive 还可以充当中介 [23、27、57],因为它旨在支持对多个独立数据管理系统的查询。通过 Hive 统一访问这些系统的好处是多方面的。
应用程序开发人员可以选择混合多个系统来实现所需的性能和功能,但他们只需要针对单个接口进行编码。因此,应用程序变得独立于底层数据系统,这为以后更改系统提供了更大的灵活性。
Hive 本身可用于实现不同系统之间的数据移动和转换,从而减轻对第三方工具的需求。
此外,作为中介的 Hive 可以通过 Ranger [12] 或 Sentry [13] 在进群范围内实施访问控制和捕获审计跟踪,还可以通过 Atlas [2] 帮助满足合规性要求。
6.1 存储处理程序
为了以模块化和可扩展的方式与其他引擎交互,Hive 包含一个需要为每个引擎实现的存储处理程序接口。 存储处理程序包括:(i) 输入格式,描述如何从外部引擎读取数据,包括如何拆分工作以增加并行度,(ii) 输出格式,描述如何将数据写入外部 引擎,(iii) 一个 SerDe(序列化器和反序列化器),它描述了如何将数据从 Hive 内部表示转换为外部引擎表示,反之亦然 (iv) Metastore 钩子,它定义了作为针对 HMS 的事务的一部分调用的通知方法,例如,当创建由外部系统支持的新表时或将新行插入该表时触发。 从外部系统读取数据的可用存储处理程序的最小实现至少包含输入格式和解码器。
一旦实现了存储处理程序接口,从 Hive 查询外部系统就很简单了,所有的复杂性都对用户隐藏在存储处理程序实现后面。
例如,Apache Druid [4, 58] 是一个开源数据存储,专为事件数据的商业智能 (OLAP) 查询而设计,广泛用于支持面向用户的分析应用程序;Hive 提供了一个 Druid 存储处理程序,因此它可以利用其效率来执行交互式查询。
要开始从 Hive 查询 Druid,唯一需要的操作是从 Hive 注册或创建 Druid 数据源。首先,如果 Druid 中已经存在数据源,我们可以通过简单的语句将 Hive 外部表映射到它:
1 | |
请注意,我们不需要为数据源指定列名或类型,因为它们是从 Druid 元数据中自动推断出来的。 反过来,我们可以使用如下简单语句在 Hive 中创建 Druid 中的数据源:
1 | |
一旦 Druid 源在 Hive 中作为外部表可用,我们就可以对它们执行任何允许的表操作。
6.2 使用 Calcite 推动计算
Hive 最强大的功能之一是可以利用 Calcite 适配器 [19] 将复杂的计算推送到支持的系统并以这些系统支持的语言生成查询。
继续 Druid 示例,查询 Druid 的最常见方式是通过 HTTP 上的 REST API 使用 JSON 表示的查询。 一旦用户声明了存储在 Druid 中的表,Hive 就可以从输入 SQL 查询透明地生成 Druid JSON 查询。 特别是,优化器应用匹配计划中的一系列操作符的规则,并生成一个新的等效序列,在 Druid 中执行更多操作。 一旦我们完成了优化阶段,需要由 Druid 执行的运算符子集由 Calcite 转换为有效的 JSON 查询,该查询附加到将从 Druid 读取的扫描运算符。 请注意,对于支持 Calcite 自动生成的查询的存储处理程序,其输入格式需要包含将查询发送到外部系统(可能将查询拆分为多个可以并行执行的子查询)并读回查询的结果。

截至今天,Hive 可以使用 Calcite 将操作推送到 Druid 和具有 JDBC 支持的多个引擎。 图 6 描述了对存储在 Druid 中的表执行的查询,以及 Calcite 生成的相应计划和 JSON 查询。
7 绩效评估
为了研究我们工作的影响,我们使用不同的标准基准随着时间的推移评估 Hive。在本节中,我们对结果进行了总结,强调了整篇论文中提出的改进的影响。
实验装置 下面介绍的实验在由 10 个节点组成的集群上运行,这些节点由 10 Gigabit 以太网连接。 每个节点都有一个 8 核 2.40GHz Intel Xeon CPU E5-2630 v3 和 256GB RAM,并有两个 6TB 磁盘用于 HDFS 和 YARN 存储。
7.1 与以前版本的比较
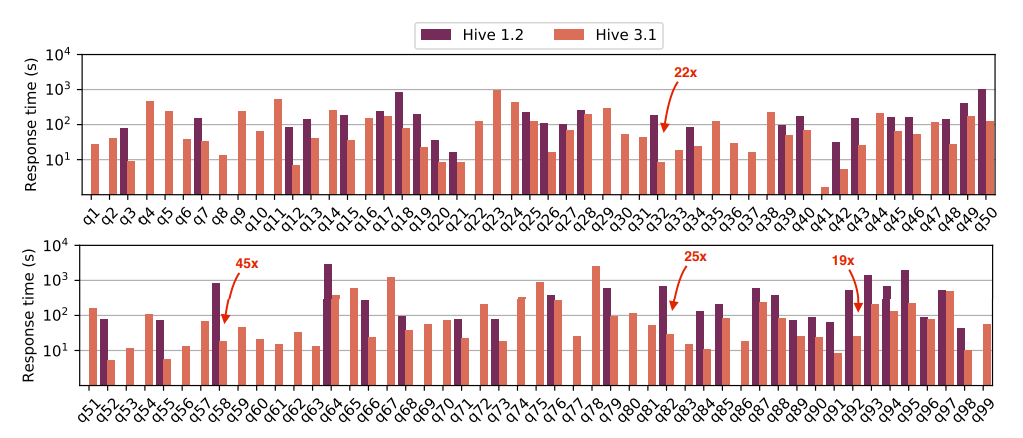
我们在 10TB 规模的数据集上使用 TPC-DS 查询进行了实验。数据使用 ORC 文件格式存储在 HDFS 中的 ACID 表中,事实表按天分区。
这些结果的可重复性所需的所有信息都是公开的。我们比较了 Hive [7] 的两个不同版本:(i) Hive v1.2,于 2015 年 9 月发布,运行在 Tez v0.5 之上,(ii) 最新的 Hive v3.1,于 11 月发布 2018 年,使用启用了 LLAP 的 Tez v0.9。
图 7 显示了两个 Hive 版本的响应时间(由用户感知);注意对数 y 轴。对于每个查询,我们报告了三个命中缓存的平均值。首先,观察在 Hive v1.2 中只能执行 50 个查询;图中省略了无法执行的查询的响应时间值。
原因是 Hive v1.2 缺乏对集合操作的支持,例如 EXCEPT 或 INTERSECT、具有非等连接条件的相关标量子查询、区间表示法和未选择列的排序以及其他 SQL 功能。
对于这 50 个查询,Hive v3.1 的性能明显优于之前的版本。特别是,Hive v3.1 平均快了 4.6 倍,最高快了 45.5 倍(参见 q58)。
图中强调了改进超过 15 倍的查询。更重要的是,由于对 SQL 支持的改进,Hive v3.1 可以执行完整的 99 个 TPC-DS 查询。
两个版本之间的性能差异如此之大,以至于 Hive v3.1 执行的所有查询的聚合响应时间仍然比 Hive v1.2 中 50 个查询的时间低 15%。
新的优化功能,例如共享工作优化器,本身就产生了很大的不同;例如,启用 q88 后,它的速度提高了 2.7 倍。
7.2 LLAP 加速
| 执行模式 | 总响应时长(s) |
|---|---|
| 容器化(未开启 LLAP) | 41576 |
| LLAP | 15540 |
表 1:使用 LLAP 之后的相应时间性能提升。
为了说明 LLAP 对使用 Tez 容器执行查询的优势,我们使用相同的配置在 Hive v3.1 中运行所有 99 个 TPC-DS 查询,但启用/禁用了 LLAP。 表 1 显示了实验中所有查询的聚合时间;我们可以观察到,LLAP 本身可以将工作负载响应时间显着降低 2.7 倍。
7.3 Druid 上的联邦查询
在下文中,我们说明了可以从使用 Hive 的物化视图和联邦功能的组合中获得的显着性能优势。对于这个实验,我们在 1TB 规模的数据集上使用 Star-Schema Benchmark (SSB) [47]。
SSB 基准测试基于 TPC-H,旨在模拟迭代和交互式查询数据仓库的过程,以播放假设场景、深入挖掘并更好地了解趋势。
它由一个事实表和 4 个维度表组成,工作负载包含 13 个查询,这些查询在不同的表集上连接、聚合和放置相当严格的维度过滤器。
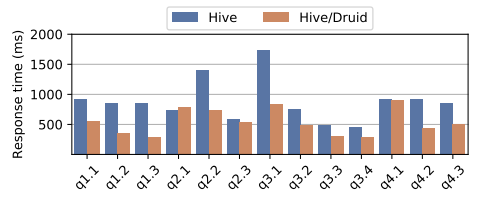
对此实验,我们创建了一个非规范化数据库模式的物化视图。物化存储在 Hive 中。然后我们在基准中运行查询,这些查询由优化器自动重写,以从物化视图中得到响应。 随后,我们将物化视图存储在 Druid v0.12 中并重复相同的步骤。图 8 描述了每个变体的响应时间。 观察到 Hive/Druid 比 Hive 中本地存储的物化视图的执行速度快 1.6 倍。原因是 Hive 使用 Calcite 将大部分查询计算推送到 Druid,因此它可以受益于 Druid 为这些查询提供更低的延迟。
8 讨论
在本节中,我们将讨论这项工作中提出的改进的影响,以及在实施这些新功能时面临的多重挑战和经验教训。
随着时间的推移,应该添加到项目中的功能面向于用户面临的缺陷,Hive 社区中的报告,或将项目商业化的公司决定。
例如,企业用户要求实施 ACID 保证,以便卸载在 Hadoop 产生之前很久就存在的数据仓库。此外,最近生效的新法规(赋予个人要求删除个人数据的权利的欧洲 GDPR)也强调了这一新功能的重要性。 毫不奇怪,ACID 支持已迅速成为在 Hadoop 之上选择 Hive 而不是其他 SQL 引擎的关键区别。 但是,将 ACID 功能引入 Hive 并不简单,初始实现必须进行重大更改,因为与非 ACID 表相比,它引入了读取延迟损失,这是用户无法接受的。 这是由于原始设计中的一个细节,我们没有预见到它会对生产性能产生如此大的影响:使用单一 delta type 的文件来存储插入、更新和删除的记录。 如果工作负载包含大量写入操作或压缩运行不够频繁,则文件读取器必须对大量基本文件和增量文件执行排序合并以整合数据,这可能会造成内存压力。 此外,过滤器下推以跳过读取整个行组不能应用于这些增量文件。本文中描述的 ACID 的第二个实现是随 Hive v3.1 推出的。它解决了上述问题,性能与非 ACID 表相当。
随着时间的推移,Hive 用户的另一个常见且频繁的请求是改善其运行时延迟。LLAP 开发始于 4 年前,旨在解决系统架构固有的问题,例如缺乏数据缓存或长时间运行的执行程序。 来自初始部署的反馈很快被纳入系统。例如,由于用户查询之间的集群资源争用,可预测性是生产中的一个巨大问题,这导致了工作负载管理器的实施。 目前,看到公司部署 LLAP 来为多租户集群中的 TB 数据提供查询服务,实现秒级的平均延迟是非常值得的。
另一个重要的决定是与 Calcite 集成以进行查询优化。在正确的抽象级别表示查询对于在 Hive 中实现高级优化算法至关重要,这反过来又为系统带来了巨大的性能优势。 此外,利用该集成可以轻松地生成查询,以便与其他系统进行联合。由于现在组织使用过多的数据管理系统很常见,因此 Hive 用户对这一新功能感到非常兴奋。
9 路线图
对 Hive 的持续改进 社区将继续致力于本文讨论的领域,以使 Hive 成为更好的仓储解决方案。例如,基于我们已经完成的支持 ACID 功能的工作,我们计划实现多语句事务。
此外,我们将继续改进 Hive 中使用的优化技术。在运行时捕获的用于查询重新优化的统计信息已经保存在 HMS 中,这将使我们能够将该信息反馈到优化器中以获得更准确的估计,类似于其他系统 [53, 60]。
物化视图工作仍在进行中,最需要的功能之一是为 Hive 实现顾问或推荐器 [1, 61]。对 LLAP 性能和稳定性的改进以及与其他专业系统(例如 Kafka [9, 43])的新连接器的实施也在进行中。
独立元存储 HMS 已成为 Hadoop 中的关键部分,因为它被 Spark 或 Presto 等其他数据处理引擎用于为中央存储库提供有关每个系统中所有数据源的信息。 因此,从 Hive 中分离出 Metastore 并将其作为独立项目开发的兴趣和正在进行的工作越来越多。这些系统中的每一个都将在 Metastore 中拥有自己的目录,并且可以更轻松地跨不同引擎访问数据。
云中的容器化 Hive 基于云的数据仓库解决方案,如 Azure SQL DW [18]、Redshift [33, 49]、BigQuery [21, 46] 和 Snowflake [29, 51] 在过去几年中越来越受欢迎。
此外,人们对 Kubernetes [44] 等系统越来越感兴趣,以为在本地或云端部署的应用程序提供容器编排。
Hive 的模块化架构可以轻松隔离其组件(HS2、HMS、LLAP)并在容器中运行它们。正在进行的工作重点是完成使用 Kubernetes 在商业云中部署 Hive 的工作。
10 结论
Apache Hive 的早期成功源于利用众所周知的接口进行批处理操作的并行性的能力。它使数据加载和管理变得简单,优雅地处理节点、软件和硬件故障,无需昂贵的修复或恢复时间。
在本文中,我们展示了社区如何将系统的实用性从 ETL 工具扩展到成熟的企业级数据仓库。我们描述了添加一个事务系统,该系统非常适合星型数据库中所需的数据修改。 我们展示了将查询延迟和并发性带入交互式操作领域所必需的主要运行时改进。我们还描述了处理当今视图层次结构和大数据操作所必需的基于成本的优化技术。 最后,我们展示了 Hive 如何在今天用作多个存储和数据系统的关系前端。所有这一切的发生在都没有损害使其流行的系统的原始特征的基础上。
Apache Hive 架构和设计原则已被证明在当今的分析环境中非常强大。我们相信,随着新的部署和存储环境的出现,它将继续在新的部署和存储环境中蓬勃发展,正如今天在容器化和云中所展示的那样。
致谢
1 | |
参考资料
[1] Sanjay Agrawal, Surajit Chaudhuri, and Vivek R. Narasayya. 2000. Automated Selection of Materialized Views and Indexes in SQL Databases. In PVLDB.
[2] Apache Atlas 2018. Apache Atlas: Data Governance and Metadata framework for Hadoop. http://atlas.apache.org/.
[3] Apache Calcite 2018. Apache Calcite: Dynamic data management framework. http://calcite.apache.org/.
[4] Apache Druid 2018. Apache Druid: Interactive analytics at scale. http://druid.io/.
[5] Apache Flink 2018. Apache Flink: Stateful Computations over Data Streams. http://flink.apache.org/.
[6] Apache HBase 2018. Apache HBase. http://hbase.apache.org/.
[7] Apache Hive 2018. Apache Hive. http://hive.apache.org/.
[8] Apache Impala 2018. Apache Impala. http://impala.apache.org/.
[9] Apache Kafka 2018. Apache Kafka: A distributed streaming platform. http://kafka.apache.org/.
[10] Apache ORC 2018. Apache ORC: High-Performance Columnar Storage for Hadoop. http://orc.apache.org/.
[11] Apache Parquet 2018. Apache Parquet. http://parquet.apache.org/.
[12] Apache Ranger 2018. Apache Ranger: Framework to enable, monitor and manage comprehensive data security across the Hadoop platform. http://ranger.apache.org/.
[13] Apache Sentry 2018. Apache Sentry: System for enforcing fine grained role based authorization to data and metadata stored on a Hadoop cluster. http://sentry.apache.org/.
[14] Apache Spark 2018. Apache Spark: Unified Analytics Engine for Big Data. http://spark.apache.org/.
[15] Apache Tez 2018. Apache Tez. http://tez.apache.org/.
[16] Apache Thrift 2018. Apache Thrift. http://thrift.apache.org/.
[17] Peter M. G. Apers, Alan R. Hevner, and S. Bing Yao. 1983. Optimization Algorithms for Distributed Queries. IEEE Trans. Software Eng. 9, 1(1983), 57–68.
[18] Azure SQL DW 2018. Azure SQL Data Warehouse. mhttp://azure.microsoft.com/en-us/services/sql-data-warehouse/.
[19] Edmon Begoli, Jesús Camacho-Rodríguez, Julian Hyde, Michael J. Mior, and Daniel Lemire. 2018. Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources. In SIGMOD.
[20] Philip A. Bernstein, Nathan Goodman, Eugene Wong, Christopher L. Reeve, and James B. Rothnie Jr. 1981. Query Processing in a System for Distributed Databases (SDD-1). ACM Trans. Database Syst. 6, 4 (1981), 602–625.
[21] BigQuery 2018. BigQuery: Analytics Data Warehouse. http://cloud.google.com/bigquery/.
[22] Vinayak R. Borkar, Michael J. Carey, Raman Grover, Nicola Onose, and Rares Vernica. 2011. Hyracks: A flexible and extensible foundation for data-intensive computing. In ICDE.
[23] Francesca Bugiotti, Damian Bursztyn, Alin Deutsch, Ioana Ileana, and Ioana Manolescu. 2015. Invisible Glue: Scalable Self-Tunning MultiStores. In CIDR.
[24] Michael J. Cahill, Uwe Röhm, and Alan David Fekete. 2008. Serializable isolation for snapshot databases. In SIGMOD.
[25] Jesús Camacho-Rodríguez, Dario Colazzo, Melanie Herschel, Ioana Manolescu, and Soudip Roy Chowdhury. 2016. Reuse-based Optimization for Pig Latin. In CIKM.
[26] Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. 2015. Apache Flink™: Stream and Batch Processing in a Single Engine. IEEE Data Eng. Bull. 38, 4 (2015), 28–38.
[27] Michael J. Carey, Laura M. Haas, Peter M. Schwarz, Manish Arya, William F. Cody, Ronald Fagin, Myron Flickner, Allen Luniewski, Wayne Niblack, Dragutin Petkovic, Joachim Thomas, John H. Williams, and Edward L. Wimmers. 1995. Towards Heterogeneous Multimedia Information Systems: The Garlic Approach. In RIDE-DOM Workshop.
[28] Surajit Chaudhuri, Ravi Krishnamurthy, Spyros Potamianos, and Kyuseok Shim. 1995. Optimizing Queries with Materialized Views. In ICDE.
[29] Benoît Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, and Philipp Unterbrunner. 2016. The Snowflake Elastic Data Warehouse. In SIGMOD.
[30] DataNucleus 2018. DataNucleus: JDO/JPA/REST Persistence of Java Objects. http://www.datanucleus.org/.
[31] Jonathan Goldstein and Per-Åke Larson. 2001. Optimizing Queries Using Materialized Views: A practical, scalable solution. In SIGMOD.
[32] Timothy Griffin and Leonid Libkin. 1995. Incremental Maintenance of Views with Duplicates. In SIGMOD.
[33] Anurag Gupta, Deepak Agarwal, Derek Tan, Jakub Kulesza, Rahul Pathak, Stefano Stefani, and Vidhya Srinivasan. 2015. Amazon Redshift and the Case for Simpler Data Warehouses. In SIGMOD.
[34] Ashish Gupta and Inderpal Singh Mumick. 1995. Maintenance of Materialized Views: Problems, Techniques, and Applications. IEEE Data Eng. Bull. 18, 2 (1995), 3–18.
[35] Himanshu Gupta. 1997. Selection of Views to Materialize in a Data Warehouse. In ICDT.
[36] Himanshu Gupta, Venky Harinarayan, Anand Rajaraman, and Jeffrey D. Ullman. 1997. Index Selection for OLAP. In ICDE.
[37] Venky Harinarayan, Anand Rajaraman, and Jeffrey D. Ullman. 1996. Implementing Data Cubes Efficiently. In SIGMOD.
[38] Stefan Heule, Marc Nunkesser, and Alexander Hall. 2013. HyperLogLog in practice: algorithmic engineering of a state of the art cardinality estimation algorithm. In EDBT.
[39] Yin Huai, Ashutosh Chauhan, Alan Gates, Günther Hagleitner, Eric N. Hanson, Owen O’Malley, Jitendra Pandey, Yuan Yuan, Rubao Lee, and Xiaodong Zhang. 2014. Major technical advancements in apache hive. In SIGMOD.
[40] Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly. 2007. Dryad: distributed data-parallel programs from sequential building blocks. In EuroSys.
[41] Alekh Jindal, Shi Qiao, Hiren Patel, Zhicheng Yin, Jieming Di, Malay Bag, Marc Friedman, Yifung Lin, Konstantinos Karanasos, and Sriram Rao. 2018. Computation Reuse in Analytics Job Service at Microsoft. In SIGMOD.
[42] Marcel Kornacker, Alexander Behm, Victor Bittorf, Taras Bobrovytsky, Casey Ching, Alan Choi, Justin Erickson, Martin Grund, Daniel Hecht, Matthew Jacobs, Ishaan Joshi, Lenni Kuff, Dileep Kumar, Alex Leblang, Nong Li, Ippokratis Pandis, Henry Robinson, David Rorke, Silvius Rus, John Russell, Dimitris Tsirogiannis, Skye Wanderman-Milne, and Michael Yoder. 2015. Impala: A Modern, Open-Source SQL Engine for Hadoop. In CIDR.
[43] Jay Kreps, Neha Narkhede, and Jun Rao. 2011. Kafka : a Distributed Messaging System for Log Processing. In NetDB.
[44] Kubernetes 2018. Kubernetes: Production-Grade Container Orchestration. http://kubernetes.io/.
[45] Per-Åke Larson, Cipri Clinciu, Campbell Fraser, Eric N. Hanson, Mostafa Mokhtar, Michal Nowakiewicz, Vassilis Papadimos, Susan L. Price, Srikumar Rangarajan, Remus Rusanu, and Mayukh Saubhasik.2013. Enhancements to SQL server column stores. In SIGMOD.
[46] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, and Theo Vassilakis. 2010. Dremel: Interactive Analysis of Web-Scale Datasets. In PVLDB.
[47] Patrick E. O’Neil, Elizabeth J. O’Neil, Xuedong Chen, and Stephen Revilak. 2009. The Star Schema Benchmark and Augmented Fact Table Indexing. In TPCTC.
[48] Presto 2018. Presto: Distributed SQL query engine for big data.http://prestodb.io/.
[49] Redshift 2018. Amazon Redshift: Amazon Web Services. http://aws.amazon.com/redshift/.
[50] Bikas Saha, Hitesh Shah, Siddharth Seth, Gopal Vijayaraghavan, Arun C. Murthy, and Carlo Curino. 2015. Apache Tez: A Unifying Framework for Modeling and Building Data Processing Applications. In SIGMOD.
[51] Snowflake 2018. Snowflake: The Enterprise Data Warehouse Built in the Cloud. http://www.snowflake.com/.
[52] Mohamed A. Soliman, Lyublena Antova, Venkatesh Raghavan, Amr El-Helw, Zhongxian Gu, Entong Shen, George C. Caragea, Carlos Garcia-Alvarado, Foyzur Rahman, Michalis Petropoulos, Florian Waas, Sivaramakrishnan Narayanan, Konstantinos Krikellas, and Rhonda Baldwin. 2014. Orca: a modular query optimizer architecture for big data. In SIGMOD.
[53] Michael Stillger, Guy M. Lohman, Volker Markl, and Mokhtar Kandil. 2014. LEO - DB2’s LEarning Optimizer. In PVLDB.
[54] Michael Stonebraker and Ugur Çetintemel. 2005. “One Size Fits All”:An Idea Whose Time Has Come and Gone. In ICDE.
[55] Ashish Thusoo, Joydeep Sen Sarma, Namit Jain, Zheng Shao, Prasad Chakka, Ning Zhang, Suresh Anthony, Hao Liu, and Raghotham Murthy. 2010. Hive - a petabyte scale data warehouse using Hadoop. In ICDE.
[56] Vinod Kumar Vavilapalli, Arun C. Murthy, Chris Douglas, Sharad Agarwal, Mahadev Konar, Robert Evans, Thomas Graves, Jason Lowe, Hitesh Shah, Siddharth Seth, Bikas Saha, Carlo Curino, Owen O’Malley, Sanjay Radia, Benjamin Reed, and Eric Baldeschwieler. 2013. Apache Hadoop YARN: yet another resource negotiator. In SOCC.
[57] Gio Wiederhold. 1992. Mediators in the Architecture of Future Information Systems. IEEE Computer 25, 3 (1992), 38–49.
[58] Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, and Deep Ganguli. 2014. Druid: a real-time analytical data store. In SIGMOD.
[59] Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, and Ion Stoica. 2010. Spark: Cluster Computing with Working Sets. In USENIX HotCloud.
[60] Mohamed Zaït, Sunil Chakkappen, Suratna Budalakoti, Satyanarayana R. Valluri, Ramarajan Krishnamachari, and Alan Wood. 2017. Adaptive Statistics in Oracle 12c. In PVLDB.
[61] Daniel C. Zilio, Jun Rao, Sam Lightstone, Guy M. Lohman, Adam J. Storm, Christian Garcia-Arellano, and Scott Fadden. 2004. DB2 Design Advisor: Integrated Automatic Physical Database Design. In PVLDB.