Apache Hadoop YARN: Yet Another Resource Negotiator 中文翻译
Apache Hadoop YARN: Yet Another Resource Negotiator 中文翻译
作者:Vinod Kumar Vavilapalli, Arun C Murthy, Chris Douglas, Sharad Agarwal, Mahadev Konar, Robert Evans, Thomas Graves, Jason Lowe, Hitesh Shah Siddharth Seth, Bikas Saha, Carlo Curino, Owen O’Malley, Sanjay Radia, Benjamin Reed, Eric Baldeschwieler
版权说明
1 | |
摘要
Apache Hadoop [1] 的最初设计主要集中在运行大量的 MapReduce 作业来处理网络爬虫。
对于日益多样化的公司而言,Hadoop 已成为数据和计算集市——实际上是共享和访问数据和计算资源的地方。
这种广泛采用和无处不在的使用使初始设计远远超出其预期目标,暴露出两个主要缺点:1) 特定编程模型与资源管理基础设施的紧密耦合,迫使开发人员滥用 MapReduce 编程模型,以及 2) 作业控制流的集中处理,这导致调度器对可扩展性方面的有很高的可能性出现问题。
在本文中,我们总结了下一代 Hadoop 计算平台 YARN 的设计、开发和当前部署状态。 我们引入的新架构将编程模型与资源管理基础设施分离,并将许多调度功能(例如,任务容错)委托给每个应用程序组件。 我们提供实验证据来证明我们所做的改进,通过报告在生产环境(包括 100% 的雅虎集群)上运行 YARN 的经验来确认提高的效率,并通过讨论将几个编程框架移植到 YARN 上来确认灵活性声明。 Dryad、Giraph、Hoya、Hadoop MapReduce、REEF、Spark、Storm、Tez。
1 引言
Apache Hadoop 最初是 MapReduce [12] 的众多开源实现之一,专注于解决索引网络爬行所需的前所未有的规模。
其执行架构针对此用例进行了调整,专注于为大规模数据密集型计算提供强大的容错能力。
在许多大型网络公司和初创公司中,Hadoop 集群是存储和处理运营数据的常见场所。
更重要的是,它成为组织内工程师和研究人员可以即时且几乎不受限制地访问大量计算资源和公司的数据宝库的。 这既是 Hadoop 成功的原因,也是其最大的诅咒,因为大多数的开发人员将 MapReduce 编程模型扩展到了集群管理基板的能力之外。 一种常见的模式提交“only-map”作业以在集群中生成任意进程。 常见的例子为复制 web 服务器和分组迭代完成的计划任务负载。 开发人员为了利用物理资源,经常采取巧妙的解决方法来避开 MapReduce API 的限制。
这些限制和误用使得很多的无关的论文使用了 Hadoop 环境作为基础。 虽然许多论文都暴露了 Hadoop 架构或实现的实质性问题,但有些论文只是简单地(或多或少巧妙地)谴责了这些滥用的一些副作用。 现在,学术界和开源社区都很好地理解了原始 Hadoop 架构的局限性。
在本文中,我们展示了一项社区驱动的努力,旨在让 Hadoop 超越其最初的设定。
我们展示了称为 YARN 的下一代 Hadoop 计算平台,它不同于其熟悉的单体架构。
通过将资源管理功能与编程模型分离,YARN 将许多与调度相关的功能委托给每个作业的组件。
在这个新环境中,MapReduce 只是运行在 YARN 之上的应用程序之一。这种分离为编程框架的选择提供了很大的灵活性。
YARN 上可用的替代编程模型的示例包括:Dryad [18]、Giraph、Hoya、REEF [10]、Spark [32]、Storm [4] 和 Tez [2]。
在 YARN 上运行的编程框架会根据他们认为合适的方式协调应用程序内通信、执行流程和动态优化,从而实现显着的性能改进。
我们从早期架构和实施者的角度来描述 YARN 的起始、设计、开源开发和部署阶段。
2 历史和理由
在本节中,我们提供了 YARN 从实际需求中产生的历史记录。 对于起因不感兴趣的读者可以跳过本节(本节高亮了需求以便阅读),在后续的第 3 节我们提供了 YARN 架构的简述。
雅虎在 2006 年采用 Apache Hadoop 来替代其原有的平台并作为其 WebMap 应用程序的基础设施 [11],并使用该技术构建已知网络的图谱以支持其搜索引擎。
当时此网络图谱包含超过 1000 亿个节点和 1 万亿条边。
之前名为“Dreadnaught”的基础设施 [25] 已达到其在 800 台机器上的可扩展性极限,并且需要对其架构进行重大转变以适应外部网络的发展速度。
Dreadnought 已经执行了类似于 MapReduce [12] 程序的分布式应用程序,因此通过采用更具可扩展性的 MapReduce 框架,可以轻松迁移搜索管道中的重要部分。
这突出了在 Hadoop 的早期版本中一直存在的第一个要求,一直到 YARN—— [R1:] 可扩展性。
除了用于雅虎搜索的超大规模管道外,优化广告分析、垃圾邮件过滤和科学的内容优化推动了许多早期需求。
随着 Apache Hadoop 社区为越来越大的 MapReduce 作业扩展平台,围绕 [R2:] 多租户 的需求开始形成。
在这种情况下可以很好的理解工程优先级和计算平台的中间阶段。
YARN 的架构基于 MapReduce 平台发展的经验,满足了许多长期存在的需求。
在本文的其余部分,我们将假设对经典 Hadoop 架构有一般的了解,附录 A 中提供了其简要总结。
2.1 临时集群时代
一些 Hadoop 最早的用户会在少数节点上建立一个集群,将他们的数据加载到 Hadoop 分布式文件系统(HDFS [27]),通过编写 MapReduce 作业获得他们感兴趣的结果,然后将其拆除 [15]。
随着 Hadoop 容错能力的提高,持久性 HDFS 集群成为常态。
在雅虎,运营商会将“有趣”的数据集加载到共享集群中,吸引有兴趣从中获取见解的科学家。
虽然大规模计算仍然是开发的主要驱动力,但 HDFS 还获得了权限模型、配额和其他功能以改进其多租户操作。
为了解决它的一些多租户问题,雅虎开发和部署 Hadoop on Demand (HoD),它使用 Torque [7] 和 Maui [20] 在共享硬件池上分配 Hadoop 集群。
用户将他们的作业连同适当大小的计算集群的描述提交给 Torque,Torque 会将作业排入队列,直到有足够的节点可用。
一旦节点可用,Torque 将在头节点上启动 HoD 的“领导者”进程,然后该进程将与 Torque/Maui 交互以启动 HoD 的从属进程,这些进程随后为该用户生成 JobTracker 和 TaskTracker,然后接受一系列作业。
当用户释放集群时,系统会自动收集用户的日志并将节点返回到共享池。
由于 HoD 为每个作业设置了一个新集群,用户可以运行(稍微)旧版本的 Hadoop,而开发人员可以轻松测试新功能。Hadoop 每三个月发布一次重大修订。
HoD 的灵活性对于保持这种节奏至关重要——我们将这种升级依赖关系的解耦称为 [R3:] 可服务性。
随着 HDFS 的扩展,可以在其上分配更多的计算集群,从而在更多数据集上创建用户密度增加的良性循环,从而产生新的见解。
虽然 HoD 也可以部署 HDFS 集群,但大多数用户跨共享 HDFS 实例部署计算节点。 随着 HDFS 的扩展,可以在其上分配更多的计算集群,从而在更多数据集上创建用户密度增加的良性循环,从而产生新的领悟。 由于大多数 Hadoop 集群都小于雅虎最大的 HoD 作业,因此 JobTracker 很少成为瓶颈。
HoD 证明了自己是一个多功能平台,预见了 Mesos [17] 的一些品质,它将扩展框架主模型以支持并发、不同编程模型之间的动态资源分配。
HoD 也可以被视为 EC2 Elastic MapReduce 和 Azure HDInsight 产品的私有云前身——没有任何隔离和安全方面的问题。
2.2 Hadoop on Demand 的缺点
雅虎由于其中等资源利用率,最终淘汰了 HoD,转而使用共享 MapReduce 集群。
在映射阶段,JobTracker 尽一切努力将任务放置在 HDFS 中靠近其输入数据的位置,理想情况下位于存储该数据副本的节点上。
由于 Torque 在不考虑位置的情况下分配节点,授予用户 JobTracker 的节点子集可能只包含少数相关副本。鉴于大量小作业,大多数读取来自远程主机。
打击这些作业的努力取得了好坏参半的结果;虽然将 TaskTracker 分布在机架上使得共享数据集的机架内读取更有可能,但 map 和 reduce 任务之间的记录洗牌必然会跨机架,并且 DAG 中的后续作业将有更少的机会来解释其祖先中的偏差。
[R4:] 位置意识 的这一方面是 YARN 的关键要求。
Pig [24] 和 Hive [30] 等高级框架通常在 DAG 中组成 MapReduce 作业的工作流,每个工作流在计算的每个阶段过滤、聚合和投影数据。
由于在使用 HoD 时没有在作业之间调整集群的大小,集群中的大部分容量都处于闲置状态,而随后的更精简的阶段完成。
在极端但非常常见的情况下,在一个节点上运行的单个 reduce 任务可能会阻止集群被回收。在此状态下,某些作业使数百个节点处于空闲状态。
最后,作业延迟主要由分配集群所花费的时间决定。
用户在估计他们的工作需要多少个节点时可以依靠很少的启发式方法,并且通常会要求 10 的任何倍数与他们的直觉相匹配。
集群分配延迟如此之高,用户通常会与同事共享期待已久的集群,持有节点的时间比预期的要长,从而进一步增加了延迟。
虽然用户喜欢 HoD 中的许多功能,但集群利用的经济性迫使雅虎将其用户打包到共享集群中。[R5:] 高集群利用率是 YARN 的首要任务。
2.3 共享集群
最终结果是 HoD 获取的信息太少,无法对其分配做出明智的决策,其资源粒度太粗,其 API 迫使用户向资源层提供误导性的约束。
然而,迁移到共享集群并非易事。虽然 HDFS 多年来逐渐扩展,但 JobTracker 已被 HoD 与这些力量隔离开来。 当那个守卫被移除时,MapReduce 集群突然变得更大,作业吞吐量急剧增加,并且许多无辜添加到 JobTracker 的功能成为关键错误的来源。 更糟糕的是,JobTracker 故障并没有丢失单个工作流,而是导致中断,这将丢失集群中所有正在运行的作业,并要求用户手动恢复他们的工作流。
停机会导致处理管道积压,当重新启动时,会给 JobTracker 带来巨大压力。重启通常涉及手动杀死用户的作业,直到集群恢复。 由于为每个作业存储了复杂的状态,因此在重新启动期间保留作业的实现从未完全调试过。
运行一个大型的、多租户的 Hadoop 集群是很难的。虽然容错是一个核心设计原则,但暴露给用户应用程序的表面是巨大的。
鉴于单点故障暴露的各种可用性问题,持续监控集群中的工作负载是否存在功能失调的作业至关重要。
更微妙的是,由于 JobTracker 需要为它初始化的每个作业分配跟踪结构,它的准入控制逻辑包括保护自身可用性的保障措施;它可能会延迟将闲置集群资源分配给作业,因为跟踪它们的开销可能会使 JobTracker 进程不堪重负。
所有这些问题都可以归为对 [R6] 可靠性/可用性的需求。
随着 Hadoop 管理更多租户、多样化用例和原始数据,其对隔离的要求变得更加严格,但授权模型缺乏强大的、可扩展的身份验证——这是多租户集群的关键特性。
这被添加并反向移植到多个版本。 [R7:] 安全和可审计的操作必须保留在 YARN 中。
开发者逐渐强化系统以适应对资源的多样化需求,这与面向槽的资源观点不符。
虽然 MapReduce 支持广泛的用例,但它并不是所有大规模计算的理想模型。
例如,许多机器学习程序需要对数据集进行多次迭代才能收敛到结果。
如果将此流程组合为一系列 MapReduce 作业,则调度开销将显着延迟结果 [32]。
类似地,使用批量同步并行模型(BSP)可以更好地表达许多图算法,使用消息传递在顶点之间进行通信,而不是在容错、大规模 MapReduce 作业中使用繁重的全对全通信障碍 [22]。
这种不匹配成为了用户生产力的障碍,但 Hadoop 中以 MapReduce 为中心的资源模型承认没有竞争的应用程序模型。
Hadoop 在雅虎内部的广泛部署及其数据管道的严重性使这些紧张局势无法调和。用户会编写“MapReduce”程序,生成替代框架,但不会因此而气馁。
对于调度程序,它们表现为具有完全不同的资源曲线的 map-only 作业,阻碍了平台内置的假设并导致利用率低下、潜在的死锁和不稳定。
纱线必须与其用户宣布休战,并为 [R8:]编程模型多样性 提供明确的支持。
除了与新兴框架要求不匹配之外,类型化槽还会损害利用率。
虽然 map 和reduce 容量之间的分离可以防止死锁,但它也可能成为资源瓶颈。
在 Hadoop 中,两个阶段之间的重叠由用户为每个提交的作业配置;稍后启动 reduce 任务会增加集群吞吐量,而在作业执行的早期启动它们会减少其延迟。
map 和 reduce 槽的数量由集群操作员固定,因此休闲的 map 容量不能用于产生 reduce 任务,反之亦然。
因为两种任务类型以不同的速度完成,所以没有配置会完美平衡;当任一插槽类型变得饱和时,JobTracker 可能需要对作业初始化应用背压,从而产生典型的管道气泡。
可替代的资源使调度复杂化,但它们也使分配器能够更紧密地打包集群。这突出了对 [R9:] 灵活资源模型的需求。
虽然与 HoD 相比,迁移到共享集群提高了利用率和局部性,但它也显着缓解了对可服务性和可用性的担忧。 在共享集群中部署新版本的 Apache Hadoop 是一个精心设计的、令人遗憾的常见事件。 为了修复 MapReduce 实现中的错误,操作员必须安排停机时间、关闭集群、部署新位、验证升级,然后接受新工作。 通过将负责仲裁资源使用的平台与表达该程序的框架相结合,人们被迫同时发展它们;当运营商提高平台用户的分配效率时,必然会纳入框架的变化。 因此,升级集群需要用户停止、验证和恢复他们的管道以进行正交更改。 虽然更新通常只需要重新编译,但用户对内部框架细节的假设——或开发人员对用户程序的假设——偶尔会在集群上运行的管道上造成阻塞不兼容。
基于 Apache Hadoop MapReduce 的发展经验教训,YARN 旨在满足需求(R1-R9)。
然而,MapReduce 应用程序的庞大安装基础、相关项目的生态系统、陈旧的部署实践和紧迫的时间表无法容忍彻底的重新设计。
为了避免“第二系统综合症”[6] 的陷阱,新架构尽可能多地重用现有框架中的代码,以熟悉的模式运行,并在绘图板上留下了许多推测性的功能。
这导致了对 YARN 重新设计的最终要求:[R10:] 向后兼容性。
在本文的其余部分,我们提供了 YARN 架构的描述(第 3 节),我们报告了 YARN 在现实世界中的采用(第 4 节),提供了验证一些关键架构选择的实验证据(第 5 节)并通过将 YARN 与一些相关工作(第 6 节)进行比较来得出结论。
3 架构
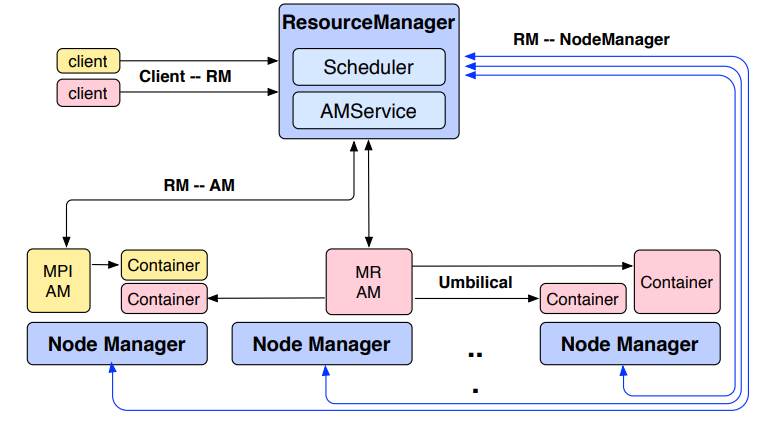
为了满足我们在第 2 节中讨论的要求,YARN 将一些功能提升到负责资源管理的平台层,将逻辑执行计划的协调留给了许多框架实现。 具体来说,每个集群的 ResourceManager (RM) 跟踪资源使用情况和节点活跃度,强制分配不变量,并仲裁租户之间的争用。 通过在 JobTracker 的章程中分离这些职责,中央分配器可以使用租户需求的抽象描述,但仍然不知道每个分配的语义。 该职责被委托给 ApplicationMaster (AM),它通过从 RM 请求资源、根据收到的资源生成物理计划以及围绕故障协调该计划的执行来协调单个作业的逻辑计划。
3.1 概览
RM 在专用机器上作为守护进程运行,并充当集群中各种竞争应用程序之间的中央权威仲裁资源。
鉴于集群资源的这种中央和全局视图,它可以在租户之间强制执行丰富的、熟悉的属性,例如公平性 [R10]、容量 [R10] 和位置 [R4]。
根据应用程序需求、调度优先级和资源可用性,RM 动态地将租用(称为容器)分配给在特定节点上运行的应用程序。
容器是绑定到特定节点 [R4,R9] 的逻辑资源包(例如,2GB RAM、1 CPU)。
为了强制执行和跟踪此类分配,RM 与在每个节点上运行的称为 NodeManager(NM) 的特殊系统守护程序交互。
RM 和 NM 之间的通信是基于心跳的可扩展性。NM 负责监控资源可用性、报告故障和容器生命周期管理(例如,启动、终止)。RM 从这些 NM 状态的快照中组合其全局视图。
作业通过公共提交协议提交给 RM,并通过准入控制阶段,在此期间验证安全凭证并执行各种操作和管理检查 [R7]。接受的作业将传递给调度程序以运行。
一旦调度程序有足够的资源,应用程序就会从接受状态转移到运行状态。除了内部记录之外,这还涉及为 AM 分配一个容器并将其生成在集群中的一个节点上。
接受的应用程序的记录被写入持久存储RM 中并在重新启动或失败的情况下恢复。
ApplicationMaster 是作业的“头”,管理所有生命周期方面,包括动态增加和减少资源消耗,管理执行流程(例如,针对映射的输出运行减速器),处理故障和计算偏差,以及执行其他本地优化。
事实上,AM 可以运行任意用户代码,并且可以用任何编程语言编写,因为与 RM 和 NM 的所有通信都是使用可扩展的通信协议进行编码的——例如考虑我们在第 4.2 节中讨论的 Dryad 端口。
YARN 对 AM 的假设很少,尽管在实践中我们预计大多数作业将使用更高级别的编程框架(例如 MapReduce、Dryad、Tez、REEF 等)。
通过将所有这些功能委托给 AM,YARN 的架构获得了极大的可扩展性 [R1]、编程模型灵活性 [R8] 和改进的升级/测试 [R3](因为同一框架的多个版本可以共存)。
通常,AM 需要利用多个节点上可用的资源(CPU、RAM、磁盘等)来完成一项工作。
为了获取容器,AM 向 RM 发出资源请求。这些请求的形式包括容器的位置偏好和属性的规范。RM 将根据可用性和调度策略尝试满足来自每个应用程序的资源请求。
当代表 AM 分配资源时,RM 会为该资源生成一个租约,该租约由随后的 AM 心跳拉取。
当 AM 将容器租约提交给 NM [R4] 时,基于令牌的安全机制可保证其真实性。
一旦 ApplicationMaster 发现一个容器可供其使用,它就会使用租约对特定于应用程序的启动请求进行编码。
在 MapReduce 中,容器中运行的代码要么是 map 任务,要么是 reduce 任务 7。
如果需要,正在运行的容器可以通过特定于应用程序的协议直接与 AM 通信,以报告状态和活跃度并接收特定于框架的命令——YARN 既不促进也不强制这种通信。
总的来说,YARN 部署为容器的生命周期管理和监控提供了一个基本但健壮的基础设施,而特定于应用程序的语义由每个框架管理 [R3,R8]。
注 7:事实上,Hadoop 1 中的 TaskTracker 生成了相同的代码 [R10]。一旦启动,进程将通过网络从 AM 而不是从本地守护进程获得有效负载。
YARN 的架构概述到此结束。在本节的其余部分,我们提供每个主要组件的详细信息。
3.2 Resource Manager (RM)
ResourceManager 公开了两个公共接口:1) 客户端提交应用程序,2) ApplicationMaster(s) 动态协商对资源的访问,以及一个面向 NodeManager 的内部接口,用于集群监控和资源访问管理。 在下文中,我们关注 RM 和 AM 之间的公共协议,因为这最能代表 YARN 平台与其上运行的各种应用程序/框架之间的重要边界。
RM 会将集群状态的全局模型与正在运行的应用程序报告的资源需求摘要进行匹配。
这使得严格执行全局调度属性成为可能(YARN 中的不同调度器关注不同的全局属性,例如容量或公平性),但它需要调度器准确了解应用程序的资源需求。
通信消息和调度程序状态必须紧凑且高效,以便 RM 能够根据应用程序需求和集群大小进行扩展 [R1]。
捕获资源请求的方式在捕获资源需求的准确性和紧凑性之间取得了平衡。幸运的是,调度程序只处理每个应用程序的整体资源配置文件,而忽略了本地优化和内部应用程序流。
幸运的是,调度程序只处理每个应用程序的整体资源配置文件,而忽略了本地优化和内部应用程序流。
YARN 完全脱离了 map 和 reduce 的静态资源划分;它将集群资源视为(离散化的)连续体 [R9]——正如我们将在第 4.1 节中看到的,这显着提高了集群利用率。
ApplicationMaster 将他们对资源的需求编码为一个或多个 ResourceRequests,每个资源请求跟踪如下内容:
- 容器数量(例如 200个)
- 每个容器所需的资源(2 GB RAM, 1 CPU,可扩展)
- 地点偏好
- 应用程序中请求的优先级
ResourceRequests 旨在允许用户捕获他们需求的完整细节和/或它的汇总版本(例如,可以指定节点级别、机架级别和全局位置首选项 [R4])。这允许将更统一的请求紧凑地表示为聚合。
此外,这种设计将允许我们对 ResourceRequests 施加大小限制,从而利用 ResourceRequests 的汇总特性对应用程序首选项进行有损压缩。
这使得调度程序可以有效地通信和存储此类请求,并允许应用程序清楚地表达他们的需求 [R1,R5,R9]。
如果无法实现完美的局部性,这些请求的汇总性质还可以指导调度程序朝着好的替代方案(例如,如果所需节点繁忙,则在该机架本地分配)。
此外,这种设计将允许我们对 ResourceRequests 施加大小限制,从而利用 ResourceRequests 的汇总特性对应用程序首选项进行有损压缩。
这种资源模型在同类环境中很好地服务于当前的应用程序,但我们预计它会随着生态系统的成熟和新需求的出现而随着时间的推移而发展。 最近和正在开发的扩展包括:显式跟踪帮派调度需求,以及软/硬约束来表达任意的协同定位或不相交的放置。
调度程序使用可用资源跟踪、更新和满足这些请求,如 NM 心跳所通告的那样。为响应 AM 请求,RM 生成容器以及授予对资源访问权限的令牌。 RM 将 NM 报告的成品容器的退出状态转发给负责的 AM。当新的 NM 加入集群时,AM 也会收到通知,以便它们可以开始请求新节点上的资源。
该协议的最新扩展允许 RM 对称地从应用程序请求返回资源。 这通常发生在集群资源变得稀缺并且调度程序决定撤销分配给应用程序以维护调度不变量的一些资源时。 我们使用类似于 ResourceRequests 的结构来捕获位置偏好(可以是严格的或可协商的)。 AM 在满足此类“抢占”请求时具有一定的灵活性,例如,通过生成对其工作不太重要的容器(例如,到目前为止仅取得很小进展的任务),通过检查任务的状态,或通过迁移计算到其他正在运行的容器。 总体而言,这允许应用程序保留工作,与强制终止容器以满足资源限制的平台形成对比。 如果应用是非协作的,RM 可以在等待一定时间后,通过通知 NM 强制终止容器来获取所需的资源。
考虑到第 2 节中的预设要求,指出 ResourceManager 不负责的内容很重要。 如前所述,它不负责协调应用程序执行或任务容错,但也不负责 1) 提供运行应用程序的状态或指标(现在是 ApplicationMaster 的一部分),也不负责 2) 提供已完成作业的框架特定报告(现在委托给每个框架的守护进程)。 这与 ResourceManager 应该只处理实时资源调度的观点一致,并帮助 YARN 中的中心组件扩展到 Hadoop 1.0 JobTracker 之外。
3.3 Application Master (AM)
应用程序可能是一组静态进程、工作的逻辑描述,甚至是长期运行的服务。 ApplicationMaster 是协调应用程序在集群中执行的进程,但它本身就像任何其他容器一样在集群中运行。 RM 的一个组件为容器协商以产生这个引导过程。
AM 定期向 RM 发出心跳以确认其活跃度并更新其需求记录。在构建其需求模型后,AM 在发送给 RM 的心跳消息中对其偏好和约束进行编码。
作为对后续心跳的响应,AM 将收到绑定到集群中特定节点的资源包的容器租用。根据从 RM 接收到的容器,AM 可以更新其执行计划以适应感知的丰富性或稀缺性。
与某些资源模型相反,对应用程序的分配是后期绑定的:产生的进程不绑定到请求,而是绑定到租约。
导致 AM 发出请求的条件在收到其资源时可能不会保持正确,但容器的语义是可替代的且特定于框架的 [R3,R8,R10]。
AM 还将向 RM 更新其资源请求,因为它收到的容器会影响其当前和未来的需求。
举例来说,MapReduce AM 优化了具有相同资源需求的 map 任务之间的局部性。在 HDFS 上运行时,每个输入数据块都在 k 台机器上复制。 当 AM 接收到一个容器时,它将它与一组挂起的 map 任务进行匹配,选择一个输入数据接近容器的任务。 如果 AM 决定在容器中运行 map 任务 mi,那么存储 mi 输入数据副本的主机就不太理想了。AM 将更新其请求以减少其他 k-1 台主机的权重。 主机之间的这种关系对 RM 来说仍然是不透明的;同样,如果 mi 失败,AM 负责更新其需求以进行补偿。 在 MapReduce 的情况下,请注意 Hadoop JobTracker 提供的一些服务——例如通过 RPC 的作业进度、状态的 Web 界面、对 MapReduce 特定历史数据的访问——不再是 YARN 架构的一部分。 这些服务要么由 ApplicationMaster 提供,要么由框架守护进程提供。
由于 RM 不解释容器状态,AM 通过 RM 确定 NM 报告的容器退出状态成功或失败的语义。由于 AM 本身就是一个运行在不可靠硬件集群中的容器,因此它应该能够抵御故障。 YARN 为恢复提供了一些支持,但由于容错和应用程序语义是如此紧密地交织在一起,所以大部分负担落在了 AM 上。我们在 3.6 节讨论容错模型。
3.4 Node Manager (NM)
NodeManager 是 YARN 中的“worker”守护进程。它验证容器租约,管理容器的依赖关系,监控它们的执行,并为容器提供一组服务。 操作员将其配置为报告此节点上可用并分配给 YARN 的内存、CPU 和其他资源。向 RM 注册后,NM 其状态放入心跳数据中并接收指令。
YARN 中的所有容器(包括 AM)都由容器启动上下文 (CLC) 描述。
该记录包括环境变量映射、存储在可远程访问的存储中的依赖项、安全令牌、NM 服务的有效负载以及创建进程所需的命令。
在验证租约的真实性后 [R7],NM 为容器配置环境,包括使用租约中指定的资源约束初始化其监控子系统。
为了启动容器,NM 将所有必要的依赖项——数据文件、可执行文件、tarball——复制到本地存储。如果需要,CLC 还包括验证下载的凭据。
依赖关系可以在应用程序中的容器之间、由同一租户启动的容器之间、甚至在租户之间共享,如 CLC 中所指定。
NM 最终会运行垃圾收集机制检查容器未使用的依赖项。
NM 还将按照 RM 或 AM 的指示杀死容器。
当 RM 报告其拥有的应用程序已完成时,当调度程序决定为另一个租户驱逐它时,或者当 NM 检测到容器超出其租用限制 [R2,R3,R7] 时,容器可能会被终止。
当不再需要相应的工作时,AM 可能会要求杀死容器。每当容器退出时,NM 将清理其在本地存储中的工作目录。
当应用程序完成时,其容器拥有的所有资源在所有节点上都将被丢弃,包括仍在集群中运行的任何进程。
NM 还定期监视物理节点的健康状况。它监视本地磁盘的任何问题,并经常运行管理员配置的脚本,该脚本反过来可以指向任何硬件/软件问题。 当发现这样的问题时,NM 将其状态更改为不健康,并报告 RM 大致相同的状态,然后做出调度程序特定的决定,在此节点上终止容器和/或停止未来分配,直到健康问题得到解决。
除了上述之外,NM 还为在该节点上运行的容器提供本地服务。 例如,当前的实现包括一个日志聚合服务,一旦应用程序完成,它将把应用程序写入的 stdout 和 stderr 数据上传到 HDFS。
最后,管理员可以使用一组可插入的辅助服务来配置 NM。虽然容器在退出后的本地存储将被清理,但允许提升一些输出以保留直到应用程序退出。 通过这种方式,进程可能会产生在容器生命周期之外持续存在的数据,由节点管理。 这些服务的一个重要用例是 Hadoop MapReduce 应用程序,其中使用辅助服务在 map 和 reduce 任务之间传输中间数据。 如前所述,CLC 允许 AM 将有效载荷寻址到辅助服务; MapReduce 应用程序使用此通道将验证 reduce 任务的令牌传递给 shuffle 服务。
3.5 YARN 框架/面向程序编写者
从前面对核心架构的描述中,我们提取出一个 YARN 应用程序作者的职责:
- 通过将 ApplicationMaster 的 CLC 传递给 RM 来提交应用程序。
- 当 RM 启动 AM 时,它应该向 RM 注册并定期通过心跳协议通告其活跃度和要求。
- 一旦 RM 分配了一个容器,AM 就可以构建一个 CLC 在相应的 NM 上启动容器。 它还可以监视正在运行的容器的状态,并在需要回收资源时停止它。 监控容器内完成的工作进度是 AM 的职责。
- 一旦 AM 完成其工作,它应该从 RM 注销并干净地退出。
- (可选)框架作者可以在他们自己的客户端之间添加控制流以报告作业状态并公开控制平面。
即使是简单的 AM 也可能相当复杂。一个具有少量特性的分布式 shell 示例是 450 多行 Java。存在简化 YARN 应用程序开发的框架。我们将在 4.2 节中探讨其中的一些。 客户端库 - YarnClient、NMClient、AMRMClient - 与 YARN 一起提供并公开更高级别的 API,以避免针对低级别协议进行编码。增强抗故障能力的 AM 是非常重要的——包括它自己的故障。 如果应用程序公开服务或连接通信图,它也负责其安全操作的所有方面;YARN 仅保护其部署。
3.6 可靠性和容错
从一开始,Hadoop 就被设计为在商品硬件上运行。通过在其堆栈的每一层中构建容错,它向用户隐藏了从硬件故障中检测和恢复的复杂性。 YARN 继承了这一理念,尽管现在职责分布在集群中运行的 ResourceManager 和 ApplicationMaster 之间。
在撰写本文时,RM 仍然是 YARN 架构中的单点故障。RM 通过在初始化时从持久存储恢复其状态来从其自身的故障中恢复。
恢复过程完成后,它会杀死集群中运行的所有容器,包括实时 ApplicationMaster。然后它启动每个 AM 的新实例。
如果框架支持恢复——并且大多数会,为了常规容错——平台将自动恢复用户的管道 [R6]。
正在为 AM 添加足够的协议支持以在 RM 重启后继续工作。这样,当 RM 关闭时,AM 可以继续使用现有容器进行处理,并在 RM 恢复时与 RM 重新同步。
还在努力通过将 RM 被动/主动故障转移到备用节点来解决 YARN 集群的高可用性。
当 NM 发生故障时,RM 通过超时其心跳响应来检测它,将在该节点上运行的所有容器标记为已终止,并向所有正在运行的 AM 报告故障。 如果故障是暂时性的,NM将与RM重新同步,清理其本地状态,然后继续。 在这两种情况下,AM 负责对节点故障做出反应,可能会在故障期间重做由在该节点上运行的任何容器完成的工作。
由于 AM 在集群中运行,它的故障不会影响集群的可用性 [R6,R8],但是由于 AM 故障导致应用程序暂停的概率比 Hadoop 1.x 中要高。
RM 可能会在 AM 失败时重新启动 AM,但该平台不提供恢复 AM 状态的支持。重新启动的 AM 与其自己运行的容器同步也不是平台关注的问题。
例如,Hadoop MapReduce AM 将恢复其已完成的任务,但在撰写本文时,正在运行的任务——以及在 AM 恢复期间完成的任务——将被终止并重新运行。
最后,容器本身的故障处理完全留给框架。RM 从 NM 收集所有容器退出事件,并在心跳响应中将这些事件传播到相应的 AM。 MapReduce ApplicationMaster 已经侦听了这些通知,并通过从 RM 请求新容器来重试 map 或 reduce 任务。
至此,我们结束了对架构的描述,并深入探讨了 YARN 的实际执行步骤。
4 在现实中的 YARN
我们知道在几家大公司都在积极使用 YARN。以下报告我们在雅虎运行 YARN 的经验。然后我们接着讨论一些已经移植到 YARN 的流行框架。
4.1 雅虎使用 YARN 的方式
雅虎将其生产集群从经典 Hadoop 的稳定分支之一升级到 YARN。 我们在下面报告的统计数据与经典Hadoop升级前的最后30天有关,以及从升级时间(每个集群不同)到2013年6月13日的平均统计数据。 解释以下统计数据的一个重要警告:我们即将展示的结果来自大型集群的真实升级体验,其中重点是保持关键共享资源的可用性,而不是科学的可重复性/一致性,就像在典型的合成实验中一样。 为了帮助读者轻松解释结果,我们将报告一些全局统计数据,然后重点关注升级前后硬件(大部分)没有改变的大型集群,最后表征该特定集群上的工作负载转移。
4.1.1 YARN 跨集群
总之,升级后,在所有集群中,YARN 每天处理约 500,000 个作业,每天处理总计超过 230 个计算年(compute-year)。底层存储超过 350 PB。
虽然 YARN 的最初目标之一是提高可扩展性,但 Yahoo 报告说他们没有运行任何超过 4000 个节点的集群,这在 YARN 之前曾经是最大的集群规模。 YARN 提供的资源利用率的显着提高增加了每个集群可以维持的工作数量。这暂时消除了进一步扩展的需要,甚至允许运营团队推迟重新配置已退役的 7000 多个节点。
另一方面,似乎 YARN 的日志聚合组件增加了 HDFS NameNode 的压力,尤其是对于大型作业。NameNode 现在估计是雅虎集群的可扩展性瓶颈。 幸运的是,社区正在进行大量工作,以通过优化 YARN 日志聚合来提高 NameNode 吞吐量并限制 NameNode 的压力。 在一些具有大量小型应用程序的大型集群上观察到 YARN 中的可扩展性问题,但最近在心跳处理方面的改进已经缓解了其中的一些问题。
4.1.2 特定集群的统计信息
我们现在将关注雅虎集群运营团队在一个特定的 2500 个节点集群上运行 YARN 的经验和统计数据。
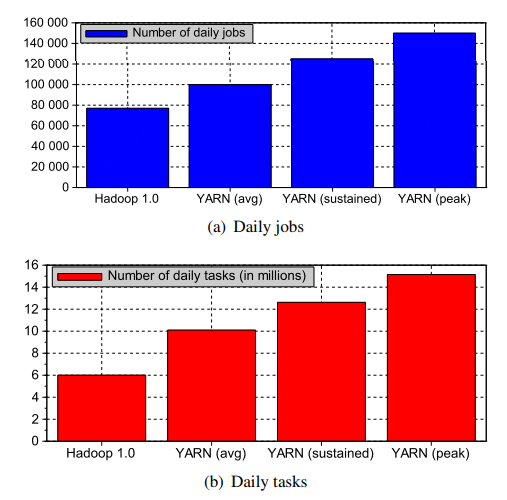
图 2 显示了运维团队在 2500 台机器集群上运行时的负载前后情况。这是雅虎最繁忙的集群,它一直在接近其极限。 在图 2a 中,我们显示运行的作业数量显着增加:从 1.0 版 Hadoop 上的约 77k 增加到 YARN 上的约 100k 定期作业。 此外,该集群实现了每天 12.5 万个作业的持续吞吐量,峰值约为每天 15 万个作业(或几乎是该集群之前舒适区的作业数量的两倍)。 平均作业大小从 58 个 map、20 个 reduce 增加到 85 个 map、16 个 reduce - 请注意,这些作业包括用户作业以及由系统应用程序产生的其他小作业,例如通过 distcp、Oozie [19] 和其他的数据复制/传输数据管理框架。 同样,所有作业的任务数量从 Hadoop 1.0 上的 4M 增加到 YARN 上的平均约 10M,持续负载约为 12M,峰值约为 15M——见图 2。
评估集群管理系统效率的另一个关键指标是平均资源利用率。同样,工作负载的变化使我们将要讨论的统计数据对直接比较的用处不大,但我们观察到 CPU 利用率显着增加。 在 Hadoop 1.0 上,估计的 CPU 利用率 11 徘徊在 320% 左右或 3.2/16 个内核,与 2500 台机器中的每台机器挂钩。 从本质上讲,转向 YARN,CPU 利用率几乎翻了一番,相当于每盒 6 个连续挂钩的核心,峰值高达 10 个充分利用的核心。总的来说,这表明 YARN 能够保持大约 2.8*2500 = 7000 个以上的内核完全忙于运行用户代码。 这与我们上面讨论的集群上运行的作业和任务数量的增加是一致的。部分解释这些改进的最重要的架构差异之一是删除了 map 和 reduce 插槽之间的静态拆分。
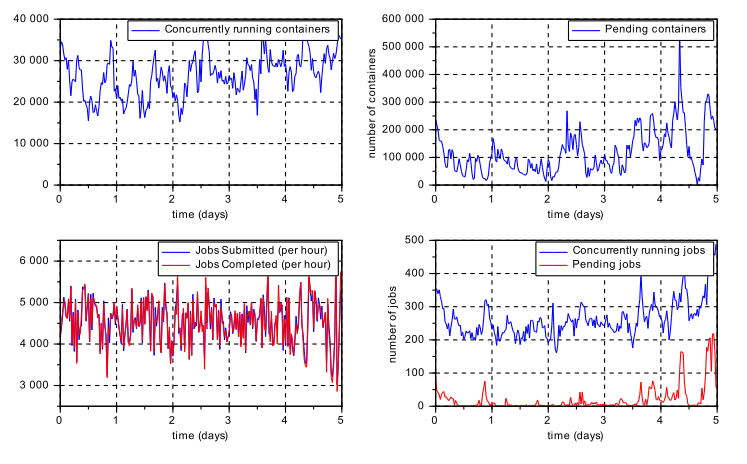
在图 3 中,我们绘制了随时间变化的几个作业统计信息:并发运行和挂起的容器、已提交、已完成、正在运行和挂起的作业。这显示了资源管理器处理大量应用程序、容器请求和执行的能力。 此集群中使用的 CapacityScheduler 版本尚未使用抢占,因为这是最近添加的功能。 虽然抢占尚未进行大规模测试,但我们相信谨慎使用抢占将显着提高集群利用率,我们在第 5.3 节中展示了一个简单的微基准测试。
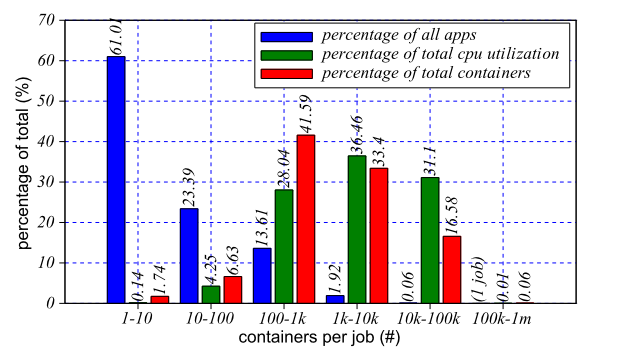
为了进一步表征在该集群上运行的工作负载的性质,我们在图 4 中展示了不同规模应用程序的直方图,描述了:1) 每个桶中的应用程序总数,2) 该桶中应用程序使用的 CPU 总量,和 3) 该存储桶中的应用程序使用的容器总数。 正如过去所观察到的,虽然大量应用程序非常小,但它们只占集群容量的一小部分(在这个 2500 台机器集群中,大约有 3.5 台机器的 CPU)。 有趣的是,如果我们比较插槽利用率与 CPU 利用率,我们会发现大型作业似乎为每个容器使用了更多的 CPU。 这与更好地调整大型作业(例如,一致使用压缩)以及可能运行更长时间的任务一致,从而分摊启动开销。
总体而言,雅虎报告称,为了将 YARN 强化为生产就绪、可扩展的系统而进行的工程工作非常值得。计划升级到最新版本 2.1-beta,继续快速升级。 经过超过 36,000 年的汇总计算时间和几个月的生产压力测试,雅虎的运营团队确认 YARN 的架构转变对其工作负载非常有益。 这在下面的引用中得到了很好的总结:“升级到 YARN 相当于添加 1000 台机器(到这个 2500 台机器集群)”。
4.2 应用程序和框架
YARN 的一个关键要求是实现更大的编程模型灵活性。尽管在撰写本文时 YARN 处于新的测试状态,但 YARN 已经吸引的许多编程框架已经验证了这一点。我们简要总结了一些 YARN 原生或移植到平台的项目,以说明其架构的通用性。
Apache Hadoop MapReduce 已经在具有几乎相同功能集的 YARN 之上运行。 它经过大规模测试,其余生态系统项目(如 Pig、Hive、Oozie 等)经过修改以在 YARN 上的 MR 之上工作,以及与经典 Hadoop 相比性能相当或更好的标准基准测试。 MapReduce 社区已确保针对 1.x 编写的应用程序可以以完全二进制兼容的方式(mapred API)或仅通过重新编译(mapreduce API 的源代码兼容性)在 YARN 之上运行。
Apache Tez 是一个 Apache 项目(在撰写本文时为孵化器),旨在提供一个通用的有向循环图(DAG) 执行框架。 它的目标之一是提供一组可以组合成任意 DAG 的构建块(包括一个简单的 2 阶段(Map 和 Reduce) DAG,以保持与 MapReduce 的兼容性)。 Tez 为 Hive 和 Pig 等查询执行系统提供了更自然的执行计划模型,而不是强制将这些计划转换为 MapReduce。 当前的重点是加速复杂的 Hive 和 Pig 查询,这些查询通常需要多个 MapReduce 作业,允许作为单个 Tez 作业运行。 未来将考虑丰富的功能,例如对交互式查询的通用支持和通用 DAG。
Spark 是加州大学伯克利分校 [32] 的一个开源研究项目,其目标是机器学习和交互式查询工作负载。
利用弹性分布式数据集 (RDD) 的中心思想来实现对此类应用程序的经典 MapReduce 的显着性能改进。
spark 最近已被移植到 YARN [?]。
Dryad [18] 提供了 DAG 作为执行流的抽象,并且已经与 LINQ [31] 集成。
移植到 YARN 的版本是 100% 本地 C++ 和 C# 用于工作节点,而 ApplicationMaster 利用 Java 的薄层与本地 Dryad 图管理器周围的 ResourceManager 接口。
最终,Java 层将被与协议缓冲区接口的直接交互所取代。 Dryad-on-YARN 与其非 YARN 版本完全兼容。
Giraph 是一个高度可扩展、以顶点为中心的图计算框架。它最初设计为在 Hadoop 1.0 之上作为仅 map 作业运行,其中一个 map 是特殊的并且充当协调器。 Giraph 到 YARN 的接口很自然,执行协调器的角色由 ApplicationMaster 承担,资源是动态请求的。
Storm 是一种开源分布式实时处理引擎,旨在跨机器集群进行扩展并提供并行流处理。一个常见的用例结合了用于在线计算的 Storm 和作为批处理器的 MapReduce。 通过在 YARN 上移植 Storm,可以解除资源分配的极大灵活性。此外,对底层 HDFS 存储层的共享访问简化了多框架工作负载的设计。
REEF 元框架:YARN 的灵活性为应用程序实现者带来了潜在的巨大努力。编写 ApplicationMaster 并处理容错、执行流程、协调等各个方面的工作是一项不平凡的工作。
REEF 项目 [10] 认识到了这一点,并排除了许多应用程序通用的几个难以构建的组件。这包括存储管理、缓存、故障检测、检查点、基于推送的控制流(稍后通过实验展示)和容器重用。
框架设计者可以在 REEF 之上构建,比直接在 YARN 上构建更容易,并且可以重用 REEF 提供的许多公共服务/库。REEF 设计使其适用于 MapReduce 和 DAG 之类的执行以及迭代和交互式计算。
Hoya 是一个 Java 工具,旨在利用 YARN 按需启动动态 HBase 集群 [21]。
在 YARN 上运行的 HBase 集群也可以动态增长和收缩(在我们的测试集群中,可以在不到 20 秒的时间内添加/删除 RegionServers)。
虽然仍在探索在 YARN 中混合服务和批处理工作负载的影响,但该项目的早期结果令人鼓舞。
5 实验
在上一节中,我们通过报告大型生产部署和蓬勃发展的框架生态系统,确立了 YARN 在现实世界中的成功。在本节中,我们将展示更具体的实验结果来展示 YARN 的一些胜利。
5.1 打破排序记录
在撰写本文时,YARN 上的 MapReduce 实现正式 12 持有 Daytona 和 Indy GraySort 基准记录,排序 1.42TB/分钟。 同一系统还报告(在比赛之外)MinuteSort 结果在一分钟内排序 1.61TB 和 1.50TB,优于当前记录。 实验在 2100 个节点上运行,每个节点配备两个 2.3Ghz hexcore Xeon E5-2630、64 GB 内存和 12x3TB 磁盘。结果总结如下表所示:
| 测试方式 | 数据类型 | 数据大小 | 耗费时间 | 速率 |
|---|---|---|---|---|
| Daytona GraySort | no-skew | 102.5 TB | 72min | 1.42TB/min |
| Daytona GraySort | skew | 102.5 TB | 117min | 0.87TB/min |
| Daytona MinuteSort | no-skew | 11497.86 GB | 87.242 sec | - |
| Daytona MinuteSort | skew | 1497.86 GB | 59.223 sec | - |
| Indt MinuteSort | no-skew | 1612.22 GB | 58.027 sec | - |
完整的报告 [16] 详细描述了此实验。
5.2 MapReduce 基准测试
MapReduce 仍然是 YARN 之上最重要和最常用的应用程序。 我们很高兴地报告,与当前稳定的 Hadoop-1 版本 1.2.1 相比,大多数标准 Hadoop 基准测试在 Hadoop 2.1.0 中的 YARN 上表现更好。 下面提供了比较 1.2.1 和 2.1.0 的 260 节点集群上的 MapReduce 基准测试摘要。 每个从节点都运行 2.27GHz Intel® Xeon® CPU,共 16 个内核,具有 38GB 物理内存,每个 6x1TB 7200 RPM 磁盘,格式化为 ext3 文件系统。 每个节点的网络带宽为 1Gb/秒。 每个节点运行一个 DataNode 和一个 NodeManager,为容器分配 24GB RAM。 我们在 1.2.1 中运行 6 个 map 和 3 个 reduce,在 2.1.0 中运行 9 个容器。每个 map 占用 1.5GB JVM heap 和 2GB 总内存,而每个 reduce 占用 3GB heap 总共 4GB。 JobTracker/ResourceManager 在专用机器上运行,HDFS NameNode 也是如此。
我们将这些基准测试的结果解释如下。排序基准测试使用默认设置测量 HDFS 中 1.52 TB(每个节点 6GB)排序的端到端时间。
shuffle 基准校准仅使用合成数据将 m 个 map 的中间输出混洗到 n 个 reduce 的速度;记录既不从 HDFS 读取也不写入到 HDFS 的时间。
虽然排序基准通常会从 HDFS 数据路径的改进中受益,但这两个基准在 YARN 上的表现更好,主要是由于 MapReduce 运行时本身的显着改进:映射端排序改进,减少了对映射输出进行管道和批量传输的客户端,以及基于 Netty [3] 的服务器端 shuffle。
扫描和 DFSIO 作业是用于评估在 Hadoop MapReduce 下运行的 HDFS 和其他分布式文件系统的规范基准;表 1 中的结果是对我们实验中 HDFS 影响的粗略测量。我们对集群的访问时间太短,无法调试和表征 2.1.0 文件系统的中等性能。
尽管有这种影响,尽管 YARN 的设计针对多租户吞吐量进行了优化,但它的单个作业的性能与中央协调器相比具有竞争力。
| 测试方式 | 1.2.1 平均运行时长(s) | 2.1.0 平均运行时长(s) | 1.2.1 吞吐量(GB/s) | 2.1.0 吞吐量(GB/s) |
|---|---|---|---|---|
| RandomWriter | 222 | 228 | 7.03 | 6.84 |
| Sort | 475 | 398 | 3.28 | 3.92 |
| Shuffle | 951 | 648 | - | - |
| AM Scalability | 1020 | 353/303 | - | - |
| Terasort | 175.7 | 215.7 | 5.69 | 4.64 |
| Scan | 59 | 65 | - | - |
| Read DFSIO | 50.8 | 58.6 | - | - |
| Write DFSIO | 50.82 | 57.74 | - | - |
表 1:来自规范 Hadoop 基准测试的结果
AM 可扩展性基准测试通过使 AM 充满容器簿记职责来衡量单个作业的稳健性。表 1 包括 MapReduce AM 的两个测量值。 第一个实验限制可用资源以匹配 1.x 部署可用的插槽。当我们移除这个人为限制并允许 YARN 使用完整节点时,其性能会显着提高。 这两个实验估计了类型插槽的开销。我们还将改进的性能归因于更频繁的节点心跳和更快的调度周期,我们将在下面更详细地讨论。 由于 YARN 主要负责分发和启动应用程序,我们认为可扩展性基准是一个关键指标。
YARN 中的一些架构选择针对我们在生产集群中观察到的瓶颈。 如第 2.3 节所述,类型槽会在节点上的可替代资源供应与执行 Hadoop MapReduce 任务的语义之间造成人为的不匹配,从而损害吞吐量。 虽然第 4.1 节涵盖了聚合工作负载的收益,但我们看到了调度甚至单个作业的好处。 我们将大部分收益归因于改进的心跳处理。在 Hadoop-1 中,由于 JobTracker 中的粗粒度锁定,每个节点在大型集群中只能每 30-40 秒心跳一次。 尽管有降低延迟的巧妙解决方法,例如用于处理轻量级更新的短路路径和用于加速重要通知的自适应延迟,但 JobTracker 中的协调状态仍然是大型集群中延迟的主要原因。 相比之下,NodeManager 每 1-3 秒发送一次心跳。RM 代码更具可扩展性,但它也解决了每个请求处理一组更简单的约束。
5.3 抢占的好处
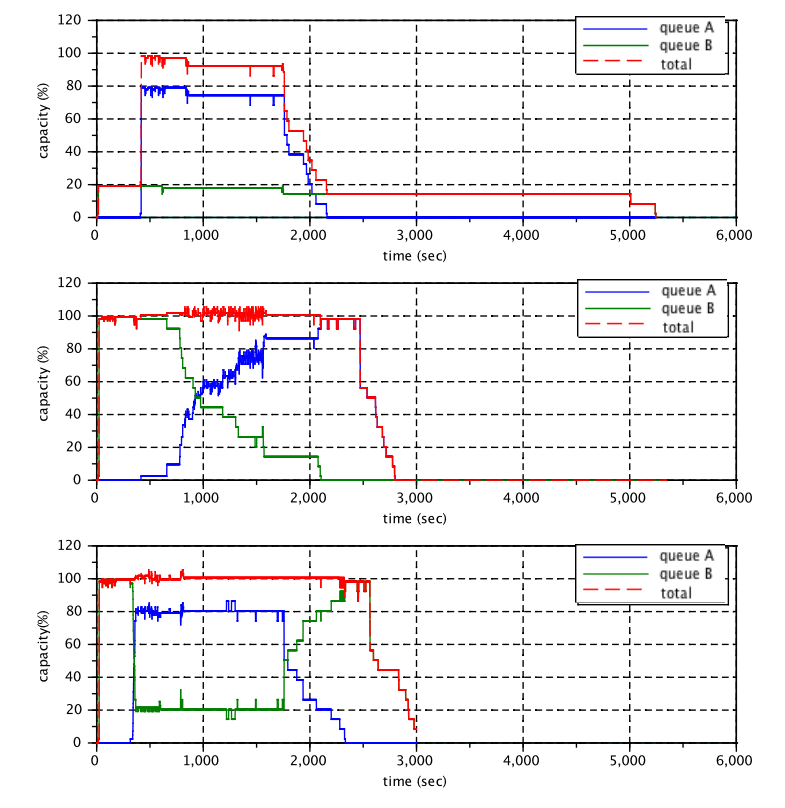
在图 5 中,我们展示了 YARN 中最近添加的一项功能:使用工作保留抢占来强制执行全局属性的能力。我们在一个小型(10 台机器)集群上进行了实验,以突出工作保留抢占的潜在影响。 集群运行 CapacityScheduler,配置了两个队列 A 和 B,分别享有 80% 和 20% 的容量。一个 MapReduce 作业在较小的队列 B 中提交,几分钟后另一个 MapReduce 作业在较大的队列 A 中提交。 在图中,我们显示了在三种配置下分配给每个队列的容量:1) 不向队列提供超出其保证的容量(固定容量) 2) 队列可能会消耗 100% 的集群容量,但不执行抢占,3) 队列可能会消耗 100% 的集群容量,但容器可能会被抢占。 工作保护抢占允许调度程序为队列 B 过度使用资源,而不必担心队列 A 中的应用程序会缺失资源而运行失败。 当队列 A 中的应用程序请求资源时,调度程序发出抢占请求,由 ApplicationMaster 通过检查点其任务和让出容器来提供服务。 这允许队列 A 在几秒钟内获得其所有保证容量(集群的 80%),而不是在情况 (2) 中,容量重新平衡需要大约 20 分钟。 最后,由于我们使用的抢占是基于检查点的并且不会浪费工作,因此在 B 中运行的作业可以从它们停止的地方重新启动任务,并且这样做很有效。
5.4 Apache Tez 相关的改进
在针对 Apache Tez 运行的 Apache Hive 上运行决策支持查询时,我们提出了一些基本改进(在撰写本文时处于早期阶段的集成)。
来自 TPC-DS 基准测试 [23] 的查询 12,涉及很少的连接、过滤器和按聚合分组。即使在积极的计划级别优化之后,Hive 在使用 MapReduce 时也会生成由多个作业组成的执行计划。
在针对 Tez 执行时,相同的查询会产生线性 DAG,单个 Map 阶段后跟多个 Reduce 阶段。
使用 MapReduce 在 20 节点集群上针对 200 个比例因子数据时,查询执行时间为 54 秒,而使用 Tez 时,查询执行时间提高到 31 秒。
大部分节省可归因于调度和启动多个 MapReduce 作业的开销,以及避免将中间 MapReduce 作业的输出持久化到 HDFS 的不必要步骤。
5.5 REEF:使用 session 降低延迟
YARN 的关键方面之一是它使构建在它之上的框架能够按照他们认为合适的方式管理容器和通信。 我们通过利用 REEF 提供的容器重用和基于推送的通信的概念来展示这一点。该实验基于一个构建在 REEF 之上的简单分布式 shell 应用程序。 我们在提交一系列 UNIX 命令(例如日期)时测量完全空闲集群上的客户端延迟。 发出的第一个命令会产生调度应用程序和获取容器的全部成本,而后续命令会通过 Client 和 ApplicationMaster 快速转发到已经运行的容器以供执行。基于推送的消息传递进一步减少了延迟。 我们实验中的加速非常显着,接近三个数量级—— 从平均超过 12 秒到 31 毫秒。
6 相关工作
其他人已经认识到经典 Hadoop 架构中的相同局限性,并同时开发了替代解决方案,可以与 YARN 进行密切比较。
在众多与 YARN 最相似的相关工作中,有:Mesos [17]、Omega [26]、Corona [14] 和 Cosmos [8],分别由 Twitter、Google、Facebook 和 Microsoft 维护和使用。
这些系统共享一个共同的灵感,以及提高可扩展性、延迟和编程模型灵活性的高级目标。许多架构差异反映了不同的设计优先级,有时只是不同历史背景的影响。 虽然无法提供真正的定量比较,但我们将尝试强调一些架构差异和我们对它们的基本原理的理解。
Omega 的设计更倾向于分布式、多级调度。 这反映了对可扩展性的更多关注,但使得执行全局属性(例如容量/公平性/截止时间)变得更加困难。 为了这个目标,作者似乎依赖于在运行时相互尊重的各种框架的协调开发。 这对于像谷歌这样的封闭世界来说是明智的,但不适用于像 Hadoop 这样的开放平台,在那里来自不同独立来源的任意框架共享同一个集群。
Corona 使用基于推送的通信,而不是 YARN 和其他框架中基于心跳的控制平面框架方法。延迟/可扩展性权衡非常重要,值得进行详细比较。
虽然 Mesos 和 YARN 都有两个级别的调度程序,但有两个非常显着的差异。首先,Mesos 是一个基于提案的资源管理器,而 YARN 有一个基于请求的实现方式。 YARN 允许 AM 根据包括位置在内的各种标准请求资源,允许请求者根据给定的内容和当前使用情况修改未来的请求。我们的方法对于支持基于位置的分配是必要的。 其次,Mesos 利用中央调度器池(例如,经典 Hadoop 或 MPI),而不是每个作业的框架内调度器。 YARN 支持将容器后期绑定到任务,其中每个单独的作业可以执行本地优化,并且似乎更适合滚动升级(因为每个作业可以在不同版本的框架上运行)。 另一方面,每个作业的 ApplicationMaster 可能会导致比 Mesos 方法更大的开销。
Cosmos 在存储和计算层的架构上与 Hadoop 2.0 非常相似,主要区别在于没有中央资源管理器。然而,它似乎只用于单一的应用程序类型:Scope [8]。
凭借更窄的目标,Cosmos 可以利用许多优化,例如本机压缩、索引文件、数据集分区的协同定位来加速 Scope。多个应用程序框架的行为不能清楚的定义。
在最近的这些努力之前,资源管理和调度方面的工作有着悠久的历史 - Condor [29]、Torque [7]、Moab [13] 和 Maui [20]。
我们早期的 Hadoop 集群使用了其中一些系统,但我们发现它们无法以一流的方式支持 MapReduce 模型。
具体来说,map 和 reduce 阶段的数据局部性和弹性调度需求都无法表达,因此被迫分配“虚拟”Hadoop,伴随着第 2.1 节中讨论的使用成本。
也许其中一些问题是由于许多这些分布式调度程序最初是为了支持 MPI 风格和 HPC 应用程序模型以及运行粗粒度的非弹性工作负载而创建的。
这些集群调度器确实允许客户端指定处理环境的类型,但不幸的是不能指定 Hadoop 的一个关键问题的位置约束。
另一类相关技术来自云基础架构领域,例如 EC2、Azure、Eucalyptus 和 VMWare 产品。这些主要针对基于 VM 的集群共享,并且通常设计用于长时间运行的进程(因为 VM 启动时间开销过高)。
7 结论
在本文中,我们总结了对 Hadoop 历史的回忆,并讨论了广泛采用和新型应用程序如何推动初始架构远远超出其设计目标。 然后,我们描述了导致 YARN 的进化但深刻的架构转型。 由于资源管理和编程框架的解耦,YARN 提供:1) 更大的可扩展性,2) 更高的效率,以及 3) 使大量不同的框架能够高效地共享一个集群。 这些说法通过实验(通过基准测试)和展示雅虎的大规模生产经验(现在 100% 在 YARN 上运行)得到证实。 最后,我们试图通过提供社区活动的快照并简要报告已移植到 YARN 的许多框架来捕捉围绕该平台的极大兴奋。 我们相信 YARN 既可以作为一个坚实的生产框架,也可以作为研究社区的宝贵游乐场。
8 致谢
1 | |
典型的 Hadoop 调度方式
在 YARN 之前,Hadoop MapReduce 集群由称为 JobTracker (JT) 的主节点和运行 TaskTracker (TT) 的工作节点组成。 用户将 MapReduce 作业提交给 JT,后者在 TT 之间协调其执行。TT 由运营商配置,具有固定数量的映射时隙和减少时隙。 TT 定期向 JT 发送心跳,以报告该节点上正在运行的任务的状态并确认其活跃度。 在心跳中,JT 更新其与该节点上运行的任务相对应的状态,代表该作业采取行动(例如,调度失败的任务以重新执行),将该节点上的空闲槽与调度程序不变量匹配,匹配符合条件的针对可用资源的作业,有利于具有该节点本地数据的任务。
作为计算集群的中央仲裁者,JT 还负责准入控制、跟踪 TT 的活跃度(重新执行正在运行的任务或输出变得不可用的任务)、 推测性地启动任务以绕过慢节点、报告作业状态 通过网络服务器向用户提供,记录审计日志和汇总统计数据,对用户进行身份验证等多项功能;每一个都限制了它的可扩展性。
参考资料
[1] Apache hadoop. http://hadoop.apache.org.
[2] Apache tez. http://incubator.apache.org/projects/tez.html.
[3] Netty project. http://netty.io.
[4] Storm. http://storm-project.net/.
[5] H. Ballani, P. Costa, T. Karagiannis, and A. I. Rowstron. Towards predictable datacenter networks. In SIGCOMM, volume 11, pages 242–253, 2011.
[6] F. P. Brooks, Jr. The mythical man-month (anniversary ed.). Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1995.
[7] N. Capit, G. Da Costa, Y. Georgiou, G. Huard, C. Martin, G. Mounie, P. Neyron, and O. Richard. A batch scheduler with high level components. In Cluster Computing and the Grid, 2005. CCGrid 2005. IEEE International Symposium on, volume 2, pages 776–783 Vol. 2, 2005.
[8] R. Chaiken, B. Jenkins, P.-A. Larson, B. Ramsey, D. Shakib, S. Weaver, and J. Zhou. Scope: easy and efficient parallel processing of massive data sets. Proc. VLDB Endow., 1(2):1265–1276, Aug. 2008.
[9] M. Chowdhury, M. Zaharia, J. Ma, M. I. Jordan, and I. Stoica. Managing data transfers in computer clusters with orchestra. SIGCOMMComputer Communication Review, 41(4):98, 2011.
[10] B.-G. Chun, T. Condie, C. Curino, R. Ramakrishnan, R. Sears, and M. Weimer. Reef: Retainable evaluator execution framework. In VLDB 2013, Demo, 2013.
[11] B. F. Cooper, E. Baldeschwieler, R. Fonseca, J. J. Kistler, P. Narayan, C. Neerdaels, T. Negrin, R. Ramakrishnan, A. Silberstein, U. Srivastava, et al. Building a cloud for Yahoo! IEEE Data Eng. Bull., 32(1):36–43, 2009.
[12] J. Dean and S. Ghemawat. MapReduce: simplified data processing on large clusters. Commun. ACM, 51(1):107–113, Jan. 2008.
[13] W. Emeneker, D. Jackson, J. Butikofer, and D. Stanzione. Dynamic virtual clustering with xen and moab. In G. Min, B. Martino, L. Yang, M. Guo, and G. Rnger, editors, Frontiers of High Performance Computing and Networking, ISPA 2006 Workshops, volume 4331 of Lecture Notes in Computer Science, pages 440–451. Springer Berlin Heidelberg, 2006.
[14] Facebook Engineering Team. Under the Hood:Scheduling MapReduce jobs more efficiently with Corona. http://on.fb.me/TxUsYN, 2012.
[15] D. Gottfrid. Self-service prorated super-computing fun. http://open.blogs.nytimes.com/2007/11/01/self-service-prorated-super-computing-fun,2007.
[16] T. Graves. GraySort and MinuteSort at Yahoo on Hadoop 0.23. http://sortbenchmark.org/Yahoo2013Sort.pdf, 2013.
[17] B. Hindman, A. Konwinski, M. Zaharia, A. Ghodsi, A. D. Joseph, R. Katz, S. Shenker, and I. Stoica. Mesos: a platform for fine-grained resource sharing in the data center. In Proceedings of the 8th USENIX conference on Networked systems design and implementation, NSDI’11, pages 22–22, Berkeley, CA, USA, 2011. USENIX Association.
[18] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: distributed data-parallel programs from sequential building blocks. In Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems 2007, EuroSys ’07, pages 59–72, New York, NY, USA, 2007. ACM.
[19] M. Islam, A. K. Huang, M. Battisha, M. Chiang, S. Srinivasan, C. Peters, A. Neumann, and A. Abdelnur. Oozie: towards a scalable workflow management system for hadoop. In Proceedings of the 1st ACM SIGMOD Workshop on Scalable Workflow Execution Engines and Technologies, page 4. ACM, 2012.
[20] D. B. Jackson, Q. Snell, and M. J. Clement. Core algorithms of the maui scheduler. In Revised Papers from the 7th International Workshop on Job Scheduling Strategies for Parallel Processing, JSSPP ’01, pages 87–102, London, UK, UK, 2001. Springer-Verlag.
[21] S. Loughran, D. Das, and E. Baldeschwieler. Introducing Hoya – HBase on YARN. http://hortonworks.com/blog/introducing-hoya-hbase-on-yarn/, 2013.
[22] G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski. Pregel: a system for large-scale graph processing. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data, SIGMOD ’10, pages 135–146, New York, NY, USA,2010. ACM.
[23] R. O. Nambiar and M. Poess. The making of tpcds. In Proceedings of the 32nd international conference on Very large data bases, VLDB ’06, pages 1049–1058. VLDB Endowment, 2006.
[24] C. Olston, B. Reed, U. Srivastava, R. Kumar, and A. Tomkins. Pig Latin: a not-so-foreign language for data processing. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, SIGMOD ’08, pages 1099–1110, New York, NY, USA, 2008. ACM.
[25] O. O’Malley. Hadoop: The Definitive Guide, chapter Hadoop at Yahoo!, pages 11–12. O’Reilly Media, 2012.
[26] M. Schwarzkopf, A. Konwinski, M. Abd-ElMalek, and J. Wilkes. Omega: flexible, scalable schedulers for large compute clusters. In Proceedings of the 8th ACM European Conference on Computer Systems, EuroSys ’13, pages 351–364, New York, NY, USA, 2013. ACM.
[27] K. Shvachko, H. Kuang, S. Radia, and R. Chansler. The Hadoop Distributed File System. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), MSST ’10, pages 1–10, Washington, DC, USA, 2010. IEEE Computer Society.
[28] T.-W. N. Sze. The two quadrillionth bit of π is 0! http://developer.yahoo.com/blogs/hadoop/twoquadrillionth-bit-0-467.html.
[29] D. Thain, T. Tannenbaum, and M. Livny. Distributed computing in practice: the Condor experience. Concurrency and Computation: Practice and Experience, 17(2-4):323–356, 2005.
[30] A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka, N. Z. 0002, S. Anthony, H. Liu, and R. Murthy. Hive - a petabyte scale data warehouse using Hadoop. In F. Li, M. M. Moro, S. Ghandeharizadeh, J. R. Haritsa, G. Weikum, M. J. Carey, F. Casati, E. Y. Chang, I. Manolescu, S. Mehrotra, U. Dayal, and V. J. Tsotras, editors, Proceedings of the 26th International Conference on Data Engineering, ICDE 2010, March 1-6, 2010, Long Beach, California, USA, pages 996–1005. IEEE,2010.
[31] Y. Yu, M. Isard, D. Fetterly, M. Budiu, U. Erlingsson, P. K. Gunda, and J. Currey. DryadLINQ: a system for general-purpose distributed data-parallel computing using a high-level language. In Proceedings of the 8th USENIX conference on Operating systems design and implementation, OSDI’08, pages 1–14, Berkeley, CA, USA, 2008. USENIX Association.
[32] M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica. Spark: cluster computing with working sets. In Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, HotCloud’10, pages 10–10, Berkeley, CA, USA, 2010. USENIX Association.