ZooKeeper Wait-free coordination for Internet-scale systems 中文翻译版
ZooKeeper: Wait-free coordination for Internet-scale systems 中文翻译版
作者:
Patrick Hunt、Mahadev Konar、Flavio P. Junqueira、Benjamin Reed
摘要
在本文中,我们描述了 ZooKeeper,一种用于协调分布式应用程序进程的服务。 由于 ZooKeeper 是关键基础设施的一部分,ZooKeeper 旨在提供一个简单且高性能的内核,用于在客户端构建更复杂的协调原语。 它在一个复制的、集中的服务中整合了来自群消息传递、共享寄存器和分布式锁服务的元素。 ZooKeeper 公开的接口具有共享寄存器的免等待特性,具有类似于分布式文件系统的缓存失效机制的事件驱动机制,以提供简单而强大的协调服务。
ZooKeeper 接口支持高性能服务实现。 除了无等待属性之外,ZooKeeper 还为每个客户端保证请求的 FIFO 执行和所有更改 ZooKeeper 状态的请求的线性化。 这些设计决策可以实现高性能处理管道并使本地服务器可以满足读取请求。 对于目标工作负载,2:1 到 100:1 的读写比率,ZooKeeper 每秒可以处理数万到数十万个事务。 这种性能允许客户端应用程序广泛使用 ZooKeeper。
1 引言
大规模分布式应用需要不同形式的协调服务。 配置是最基本的协调形式之一。 在最简单的形式中,配置只是系统进程的操作参数列表,而更复杂的系统具有动态配置参数。 组成员和领导者选举在分布式系统中也很常见:进程通常需要知道哪些其他进程还活着以及这些进程负责什么。 锁构成了一个强大的协调原语,它实现了对关键资源的互斥访问。
一种协调方法是为每个不同的协调需求开发服务。
例如,Amazon Simple Queue Service [3] 专门关注队列。
其他服务是专门为领导选举 [25] 和配置 [27] 开发的。
实现更强大原语的服务可用于实现功能较弱的原语。
例如,Chubby [6] 是一个具有强同步保证的锁定服务。
然后可以使用锁来实现领导者选举、组成员资格等。
在设计我们的协调服务时,我们不再在服务器端实现特定的原语,而是选择公开一个 API,使应用程序开发人员能够实现他们自己的原语。 这样的选择导致了协调内核的实现,该内核支持新的原语,而无需更改服务核心。 这种方法支持适应应用程序要求的多种形式的协调,而不是将开发人员限制在一组固定的原语中。
在设计 ZooKeeper 的 API 时,我们远离了阻塞原语,例如锁。 协调服务的阻塞原语可能会导致慢速或故障客户端等问题,从而对更快客户端的性能产生负面影响。 如果处理请求依赖于其他客户端的响应和故障检测,则服务本身的实现会变得更加复杂。 因此,我们的系统 ZooKeeper 实现了一个 API,该 API 可以操作简单的无等待数据对象,就像在文件系统中一样分层组织。 实际上,ZooKeeper API 类似于任何其他文件系统,仅从 API 签名来看,ZooKeeper 似乎是没有锁定方法、打开和关闭的 Chubby。 然而,实现免等待数据对象将 ZooKeeper 与基于阻塞原语(例如锁)的系统区分开来。
尽管无等待属性对于性能和容错很重要,但对于协调来说还不够。
我们还必须为运营提供订单保证。
特别是,我们发现保证所有操作的 FIFO 客户端排序和线性化写入可以有效实现服务,并且足以实现我们的应用程序感兴趣的协调原语。
事实上,我们可以使用我们的 API 为任意数量的进程实现共识,并且根据 Herlihy 的层次结构,ZooKeeper 实现了一个通用对象 [14]。
ZooKeeper 服务包含一组使用复制来实现高可用性和性能的服务器。 其高性能使包含大量进程的应用程序能够使用这样的协调内核来管理协调的所有方面。 我们能够使用简单的流水线架构来实现 ZooKeeper,该架构允许我们处理成百上千个未完成的请求,同时仍然实现低延迟。 这样的管道自然能够以 FIFO 顺序从单个客户端执行操作。 保证 FIFO 客户端顺序使客户端能够异步提交操作。 通过异步操作,客户端一次可以有多个未完成的操作。 例如,当新客户端成为领导者并且必须操作元数据并相应地更新它时,此功能是可取的。 没有多个未完成操作的可能性,初始化时间可以是秒级而不是亚秒级。
为了保证更新操作满足线性化,我们实现了一个基于领导者的原子广播协议 [23],称为 Zab [24]。
然而,ZooKeeper 应用程序的典型工作负载由读取操作主导,因此需要扩展读取吞吐量。
在 ZooKeeper 中,服务器在本地处理读操作,我们不使用 Zab 对它们进行完全排序。
在客户端缓存数据是提高读取性能的一项重要技术。 例如,一个进程缓存当前领导者的标识符而不是每次需要知道领导者时去检测 ZooKeeper。 ZooKeeper 使用监视机制使客户端能够缓存数据,而无需直接管理客户端缓存。 通过这种机制,客户端可以监视给定数据对象的更新,并在更新时收到通知。 Chubby 直接管理客户端缓存。 它阻止更新以使所有缓存正在更改的数据的客户端的缓存无效。 在这种设计下,如果这些客户端中的任何一个运行缓慢或出现故障,更新就会延迟。 Chubby 使用租约来防止有故障的客户端无限期地阻塞系统。 然而,租约只能限制慢速或故障客户端的影响,而 ZooKeeper watches 则完全避免了这个问题。
在本文中,我们将讨论 ZooKeeper 的设计和实现。 使用 ZooKeeper,我们能够实现应用程序所需的所有协调原语,即使只有写入是可线性化的。 为了验证我们的方法,我们展示了我们如何使用 ZooKeeper 实现一些协调原语。
总之,在本文中我们主要贡献有:
协调内核: 我们提出了一种在分布式系统中使用具有宽松一致性保证的无等待协调服务。 特别是,我们描述了协调内核的设计和实现,我们已在许多关键应用程序中使用它来实现各种协调技术。
协调清单: 我们展示了如何使用 ZooKeeper 来构建更高级别的协调原语,甚至是分布式应用程序中经常使用的阻塞和强一致性原语。
协调经验: 分享一些 ZooKeeper 的使用方法,并对其性能进行评估。
2 ZooKeeper 服务
客户端使用 ZooKeeper 库通过 API 向 ZooKeeper 提交请求。 除了通过 API 暴露 ZooKeeper 服务接口之外,客户端库还管理客户端和 ZooKeeper 服务器之间的网络连接。
在本节中,我们首先从架构来概览 ZooKeeper 服务。 然后我们讨论客户端用来与 ZooKeeper 交互的 API。
术语 在本文中,我们使用 client 表示 ZooKeeper 服务的用户,server 表示提供 ZooKeeper 服务的进程,znode 表示 ZooKeeper 数据中的内存数据节点, 它组织在一个分层的命名空间中,称作为数据树。 我们还使用术语更新和写入来指代任何修改数据树状态的操作。 客户端在连接到 ZooKeeper 并获取会话句柄时建立会话,并通过该句柄发出请求。
2.1 服务概览
ZooKeeper 向其客户端提供一组数据节点 (znodes) 的抽象,根据分层名称空间进行组织。 此层次结构中的 znode 是客户端通过 ZooKeeper API 操作的数据对象。 分层命名空间通常用于文件系统。 这是一种组织数据对象的理想方式,因为用户习惯于这种抽象,并且它可以更好地组织应用程序元数据。 为了引用给定的 znode,我们对文件系统路径使用标准的 UNIX 表示法。 例如,我们使用 /A/B/C 来表示 znode C 的路径,其中 C 有 B 作为其父级,B 有 A 作为其父级。 所有 znode 都存储数据,所有 znode,除了临时 znode,都可以有子节点。
客户端可以创建两种类型的 znode:
常规型(Regular):客户端通过显式创建和删除它们来操作常规 znode。 临时型(Ephemeral):客户端创建这样的 znode,他们要么明确删除它们,要么让系统在创建它们的会话终止时自动删除它们(故意或由于故障)。
此外,在创建新的 znode 时,客户端可以设置一个顺序标志。 使用顺序标志集(sequential flag)创建的节点具有附加到其名称的单调递增计数器的值。 如果 n 是新的 znode 并且 p 是父节点,则 n 的序列值永远不会小于在 p 下创建的任何其他顺序 znode 的名称中的值。
ZooKeeper 实现了 watches 以允许客户端及时接收更改通知而无需轮询。 当客户端发出设置了监视标志的读取操作时,该操作将正常完成,除非服务器承诺在返回的信息发生更改时通知客户端。 watches 是与会话相关的一次性触发器;一旦触发或会话关闭,它们将被取消注册。 watches 指示发生了更改,但不提供更改。 例如,如果客户端在 “/foo” 更改两次之前发出 getData(“/foo”, true),客户端将收到一个监视事件,告诉客户端 “/foo” 的数据已更改。 例如连接丢失事件一样的会话事件,也被发送到 watches 回调,以便客户端知道 watches 事件可能会有延迟。
数据模型 ZooKeeper 的数据模型本质上是一个 API 简化的文件系统,只有完整的数据读写,或者是一个具有层次化的键/值表。 分层命名空间对于为不同应用程序的命名空间分配子树以及设置对这些子树的访问权限非常有用。 我们还利用客户端目录的概念来构建更高级别的原语,我们将在 2.4 节中看到。
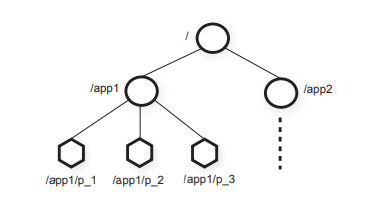
与文件系统中的文件不同,znode 不是为一般数据存储而设计的。 相反,znode 映射到客户端应用程序的抽象,通常对应于用于协调目的的元数据。 为了说明这一点,在图 1 中,我们有两个子树,一个用于应用程序 1 (/app1),另一个用于应用程序 2 (/app2)。 应用程序 1 的子树实现了一个简单的组成员协议:每个客户端进程 p_i 在 /app1 下创建一个 znode pi,只要进程正在运行,它就会一直存在。
尽管 znodes 不是为一般数据存储而设计的,但 ZooKeeper 确实允许客户端存储一些可用于分布式计算中的元数据或配置的信息。 例如,在基于领导者的应用程序中,这对于刚刚开始了解哪个其他服务器当前是领导者的应用程序服务器很有用。 为了实现这个目标,我们可以让当前的领导者将这些信息写在 znode 空间中的一个已知位置。 znode 还具有与时间戳和版本计数器相关联的元数据,这允许客户端跟踪对 znode 的更改并根据 znode 的版本执行条件更新。
会话 客户端连接到 ZooKeeper 并发起会话。 会话在到达配置的事件后会超时。 如果 ZooKeeper 在超过该超时时间而没有从其会话中收到任何内容,则认为客户端有故障。 当客户端明确关闭会话 handle 或 ZooKeeper 检测到客户端故障时,会话关闭。 在会话中,客户端观察反映其操作执行的一系列状态变化。 会话使客户端能透明地在 ZooKeeper 集合内从一台服务器移动到另一台服务器,而不中断服务。
2.2 客户端 API
我们在下面介绍 ZooKeeper API 的一个相关子集,并讨论每个请求的语义。
create(path, data, flags): 创建一个 znode 将其路径名设置为 path 并存储 data[] 数据,然后返回新 znode 的名称。 flags 标识能让客户端选择 znode 的类型,具体是常规型还是临时型。
delete(path, version): 如果 znode 处于预期版本,则删除 znode 路径。
exists(path, watch): 如果具有路径名 path 的 znode 存在,则返回 true,否则返回 false。 watch 标志使客户端能够在 znode 上设置监视。
getData(path, watch): 返回与 znode 关联的数据和元数据,例如版本信息。 watch 标志的工作方式与它对exists() 的工作方式相同,除了如果znode 不存在ZooKeeper 不会设置监视。
setData(path, data, version): 如果版本号是 znode 的当前版本,则将 data[] 写入 znode 路径。
getChildren(path, watch): 返回 znode 子节点的名称集。
sync(path): 等待所有挂起的更新操作开始传播向客户端所连接的服务器。 该路径当前被忽略。
注:即等待所有待完成的更新操作完成更新,但是忽略输入路径。
所有方法都在 API 中提供了同步和异步版本。 应用程序在需要执行单个 ZooKeeper 操作并且没有并发任务要执行时使用同步 API,因此它会进行必要的 ZooKeeper 调用并阻塞。 然而,异步 API 使应用程序能够同时执行多个未完成的 ZooKeeper 操作和其他任务。 ZooKeeper 客户端保证按顺序调用每个操作的相应回调。
值得注意的是,ZooKeeper 不使用 handle 来访问 znode。 每个请求都包含正在操作的 znode 的完整路径。 这种选择不仅简化了 API(没有 open() 或 close() 方法),而且还消除了服务器需要维护的额外状态。
每个更新方法都采用一个预期的版本号,这使得有条件更新的实现成为可能。 如果 znode 的实际版本号与预期版本号不匹配,则更新失败并出现意外版本错误。 如果版本号为 -1,则不执行版本检查。
2.3 ZooKeeper 保证
ZooKeeper 有两个基本的排序保证:
可线性写入: 所有更新 ZooKeeper 状态的请求都是可序列化的并尊重优先级。
先进先出的客户端顺序: 来自给定客户端的所有请求都按照客户端发送的顺序执行。
请注意,我们对线性化的定义与 Herlihy [15] 最初提出的定义不同,我们称之为 A-线性化(异步线性化)。
在 Herlihy 对线性化的最初定义中,一个客户端一次只能有一个未完成的操作(一个客户端是一个线程)。
在我们的情况下,我们允许一个客户端有多个未完成的操作,因此我们可以选择让同一客户端的未完成操作无须的或按照 FIFO 顺序执行。
为了符合设计需求我们选择了后者。
重要的是要观察到所有适用于可线性化对象的结果也适用于 A 可线性化对象,因为满足 A-线性化的系统也同时满足了线性化。
因为只有更新请求是 A-线性化,所以 ZooKeeper 在每个副本本地处理读取请求。
这允许服务随着服务器添加到系统而线性的进行扩张。
要了解这两种保证如何相互作用,请考虑以下场景。 由多个进程组成的系统会选举一个领导者来指挥工作进程。 当新的领导者接管系统时,它必须更改大量配置参数并在完成后通知其他进程。 然后我们有两个重要的要求:
- 当新的领导开始修改内容时,我们不希望其它的进程使用正在修改的配置。
- 如果新的领导者在配置完全更新之前死亡,我们不希望其它进程使用这个部分配置。
请注意,分布式锁(例如 Chubby 提供的锁)将有助于满足第一个要求,但不足以满足第二个要求。 有了 ZooKeeper,新的领导者可以指定一条路径作为 ready znode;其他进程只会在该 znode 存在时使用该配置。 新的 leader 通过删除 ready、更新各种配置znode、重新创建 ready 来改变配置。 所有这些变动都可以通过管道进行异步发布,以快速更新配置状态。 尽管更改操作的延迟在 2 毫秒的数量级,但如果请求一个接一个地发出,更新 5000 个不同 znode 的新领导者将花费 10 秒; 如果通过异步发出请求,则可以在 1 秒钟之内完成。 由于顺序保证,如果一个进程看到 ready znode,它也必须看到新领导者所做的所有配置更改。 如果在创建 ready znode 之前新领导者死亡,则其他进程知道配置尚未最终确定并且不会使用它。
上述方案仍然有一个问题:如果一个进程在新的领导者开始进行更改之前看到 ready znode 存在,然后在更改正在进行时开始读取配置会发生什么。 这个问题是通过通知的顺序保证来解决的:如果客户端正在观察更改,客户端将在看到更改后系统的新状态之前看到通知事件。 因此,如果读取 ready znode 的进程请求收到有关该 znode 更改的通知,它将在读取任何新配置之前看到客户端更改的通知。
当客户端除了 ZooKeeper 之外还有自己的通信通道时,会出现另一个问题。 例如,考虑两个客户端 A 和 B,它们在 ZooKeeper 中具有共享配置并通过共享通信通道进行通信。 如果 A 更改 ZooKeeper 中的共享配置并通过共享通信通道告诉 B 更改,B 将期望在重新读取配置时看到更改。 如果 B 的 ZooKeeper 副本稍微落后于 A,则它可能看不到新配置。 使用上述保证 B 可以通过在重新读取配置之前发出写入来确保它看到最新的信息。
为了更有效地处理这种情况,ZooKeeper 提供了 sync 请求:跟随进行读取的操作被称为慢读。
sync 使得服务器先完成读取请求然后再完成所有等待的写入请求而没有产生完全写入的开销。
这个原语在思想上类似于 ISIS [5] 的 flush 。
ZooKeeper 还具有以下两个活动性和持久性保证: 如果大多数 ZooKeeper 服务器处于活动状态则通信服务将可用; 如果 ZooKeeper 服务成功响应更改请求,则只要仲裁服务器最终能够恢复,该更改就会在任何数量节点的故障中正常恢复。
2.4 原语的例子
在本节中,我们将展示如何使用 ZooKeeper API 来实现更强大的原语。 ZooKeeper 服务对这些更强大的原语一无所知,因为它们完全在客户端使用 ZooKeeper 客户端 API 实现。 一些常见的原语,如组成员资格和配置管理,也是免等待的。 对于其他的,比如集合点,客户端需要等待一个事件。 即使 ZooKeeper 是无等待的,我们也可以使用 ZooKeeper 实现高效的阻塞原语。 ZooKeeper 的排序保证允许对系统状态进行有效推理,而 watches 则允许有效等待。
配置管理 ZooKeeper 可用于在分布式应用程序中实现动态配置管理。 配置以最简单的形式存储在 znode Zc 中。 进程以 Zc 的完整路径名启动。 启动进程通过读取 zc 并将 watch 标志设置为 true 来获取它们的配置。 如果 zc 中的配置被更新,进程会收到通知并读取新配置,再次将 watch 标志设置为 true。
请注意,在此方案中,与大多数其他使用 watch 的方案一样,确保进程具有最新信息。 例如,如果一个正在观察 Zc 的进程收到 Zc 更改的通知,并且在它可以为 Zc 发出读取之前, 还有三个 Zc 更改,则该进程不会收到另外三个通知事件。 这不会影响进程的行为,因为这三个事件只会通知进程它已经知道的事情:它拥有的关于 Zc 的信息是陈旧的。
集合 有时在分布式系统中,最终系统配置的外观并不总是先验清楚的。 客户端可能想要启动一个主进程和几个工作进程,但是启动进程是由调度程序完成的,因此客户端不知道它可以给工作进程连接到主进程的地址和端口等信息。 我们通过 ZooKeeper 使用客户端创建的集合点 znode Zr 来处理这种情况。 客户端将 Zr 的完整路径名作为主进程和工作进程的启动参数进行传递。 当主进程启动时,它会在 Zr 中填入有关它正在使用的地址和端口的信息。 当工作进程启动时,它会在 watch 设置为 true 的情况下读取 Zr 。 如果 Zr 尚未填写,则工作进程会等待 Zr 更新时收到通知。 如果 Zr 是一个临时节点,主进程和工作进程可以监视 Zr 的删除并在客户端结束时清理自己。
组关系 我们利用临时节点来实现组成员身份。 具体来说,我们使用临时节点允许我们查看创建节点的会话状态这一事实。 我们首先指定一个 znode Zg 来表示该组。 当组的进程成员启动时,它会在 Zg 下创建一个临时子 znode。 如果每个进程都有唯一的名称或标识符,则该名称将用作子 znode 的名称;否则,该进程会使用 SEQUENTIAL 标志创建 znode 以获得唯一的名称分配。 例如,进程可以将进程信息放入子 znode 的数据中,例如进程使用的地址和端口。
在 Zg 下创建子 znode 后,进程正常启动。 它不需要做任何其他事情。 如果进程失败或结束,在 Zg 下代表它的 znode 将被自动删除。
进程可以通过简单地列出 Zg 的子进程来获取组信息。 如果进程想要监视组成员身份的更改,则该进程可以将监视标志设置为 true 并在收到更改通知时刷新组信息(始终将监视标志设置为 true)。
简单的锁 ZooKeeper 虽然不是锁服务,但是可以用来实现锁。 使用 ZooKeeper 的应用程序通常使用根据其需要定制的同步原语,如上所示。 这里我们展示了如何使用 ZooKeeper 实现锁,以表明它可以实现多种通用同步原语。
最简单的锁实现使用 “锁文件”。 锁由一个 znode 表示。 为了获取锁,客户端尝试使用 EPHEMERAL 标志创建指定的 znode。 如果创建成功,客户端持有锁。 否则,如果当前领导者死亡,客户端可以读取设置了监视标志的 znode 以得到通知。 客户端在死亡或显式删除 znode 时释放锁。 等待锁的其他客户端一旦观察到 znode 被删除,就会再次尝试获取锁。
虽然这个简单的锁定协议有效,但它确实存在一些问题。 首先,它受到羊群效应(herd effect)的影响。 如果有很多客户端在等待获取锁,即使只有一个客户端可以获取锁,他们也会在锁被释放时争夺锁。 其次,它只实现了排他锁。 以下两个原语展示如何克服这两个问题。
解决羊群效应简单锁 我们定义了一个锁 znode l 来实现这样的锁。 直观地,我们将所有请求锁定的客户端排列起来,每个客户端按照请求到达的顺序获得锁定。
加锁
1 | |
解锁
1 | |
在 Lock 部分的第 1 行中使用 SEQUENTIAL 标志命令使应用程序按顺序申请锁。 如果客户端的 znode 在第 3 行具有最低的序列号,则客户端持有锁。 否则,客户端会等待加锁程序删除 znode 或者从持有锁的客户端获得锁。 通过观测客户端 znode 之前获得锁的 znode,我们避免了羊群效应,当锁被释放或锁请求被放弃时,我们只唤醒一个进程。 一旦客户端正在监视的 znode 消失,客户端必须检查它现在是否持有锁。 (之前的锁请求可能已经被放弃,并且有一个序列号较低的 znode 仍在等待或持有锁。)
释放锁就像删除代表锁请求的 znode n 一样简单。 通过在创建时使用 EPHEMERAL 标志,崩溃的进程将自动清除任何锁请求或释放它们可能拥有的任何锁。
综上所述,这种加锁方案有以下优点:
- 删除一个 znode 只会导致一个客户端唤醒,因为每个 znode 正好被另一个客户端监视,所以我们不会受羊群效应影响。
- 没有轮询或超时。
- 由于我们实现了锁的方式,我们可以通过浏览 ZooKeeper 的数据看到锁争用的数量,断锁,以及调试锁。
读/写锁 为了实现读/写锁,我们稍微改变了锁程序,并有单独的读锁和写锁程序。 解锁过程与全局锁定情况相同。
写锁
1 | |
读锁
1 | |
此锁定过程与以前的锁定略有不同。 写锁仅在命名上有所不同。 由于读锁可能是共享的,第 3 行和第 4 行略有不同,因为只有较早的写锁 znode 会阻止客户端获取读锁。 当有多个客户端等待读锁并在删除具有较低序列号的“写” znode 时得到通知,我们可能会遇到“羊群效应”; 事实上,这是一种理想的行为,所有这些读取客户端都应该被释放,因为它们现在可能拥有锁。
双重屏障 双屏障使客户端能够同步计算的开始和结束。 当由屏障阈值定义的足够进程加入屏障时,进程开始运行计算并在完成后离开屏障。 我们用 znode 表示 ZooKeeper 中的屏障,称为 b。 每个进程 p 在进入屏障时都向 b 注册(通过创建一个 znode 作为 b 的子节点),在运算结束后进行注销(删除对应子节点)。 当 b 的子节点数超过屏障阈值时,进程可以进入屏障。 当所有进程都删除了它们的子进程时,进程可以离开屏障。 我们使用 watche 来有效地等待进入和退出条件得到满足。 在注册过程中,进程会观察 b 的就绪子进程的数量,然后进程会创建子进程导致子进程数量超过阈值。 在注销过程中,进程会观察运行完成的子进程,并且仅在该 znode 被删除后才检查退出条件。
3 ZooKeeper 应用程序
我们现在描述一些使用 ZooKeeper 的应用程序,并简要解释他们如何使用它。 我们以粗体显示每个示例的原语。
获取服务 数据爬取是搜索引擎的重要组成部分,而雅虎抓取了数十亿个 Web 文档。 获取服务(FS) 是雅虎爬取系统其中的一个服务。 本质上,它具有控制页面获取进程的主进程。 master 为 fetchers 提供配置,fetchers 写回通知他们的状态和健康状况。 使用 ZooKeeper for FS 的主要优点是从 master 的故障中恢复,即使出现故障也能保证可用性,以及将客户端与服务器解耦, 允许它们通过从 ZooKeeper 读取它们的状态来将它们的请求定向到健康的服务器。 因此,FS 主要使用 ZooKeeper 来管理 配置元数据(configuration metadata),尽管它也使用 ZooKeeper 来选举 master (领导选举(leader election))。
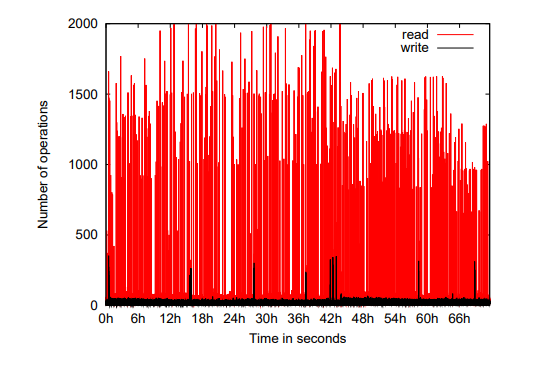
注:每个点代表一个一秒的样本。
图 2 显示了 FS 使用的 ZooKeeper 服务器在三天内的读写流量。
为了生成这个图,我们计算了该时间段内每秒的操作次数,每个点对应于该秒的操作次数。
我们观察到,与写入流量相比,读取流量要高得多。
在速率高于每秒 1000 次操作的期间,读写比率在 10:1 和 100:1 之间变化。
此工作负载中的读取操作是 getData()、getChildren() 和 exists(),按流行程度递增。
Katta
Katta [17] 是一个使用 ZooKeeper 进行协调的分布式索引器,它不是雅虎公司的应用。
Katta 使用分片来划分索引工作。
主服务器将分片分配给从服务器并跟踪进度。
主服务器也可能发生故障,因此其他服务器必须准备好在发生故障时接管。
Katta 使用 ZooKeeper 跟踪从服务器和主服务器(组成员身份)的状态,并处理主故障转移(领导选举)。
Katta 还使用 ZooKeeper 来跟踪和传播分片到从属设备的分配(配置管理)。
雅虎消息广播 雅虎消息广播服务(YMB)是一个分布式发布订阅系统。 系统管理数以千计的主题,客户端可以向这些主题发布消息和接收消息。 主题分布在一组服务器中以提供可伸缩性。 每个主题都使用主备份方案进行复制,以确保将消息复制到两台机器以确保可靠的消息传递。 组成 YMB 的服务器使用无共享分布式架构,这使得协调对于正确操作至关重要。 YMB 使用 ZooKeeper 管理主题的分发(配置元数据(configuration metadata)), 处理系统中机器的故障(故障检测和组成员身份(failure detection, group membership)),并控制系统运行。
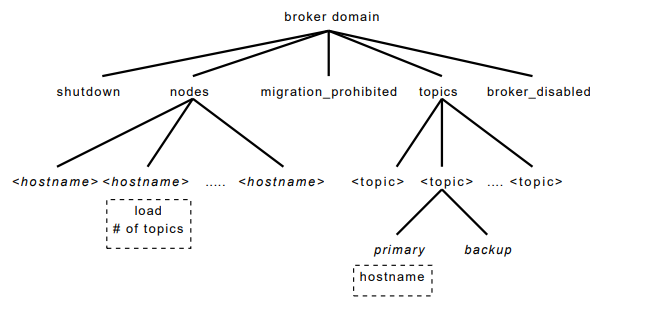
图 3 显示了 YMB 的部分 znode 数据结构。 每个代理域都有一个称为节点的 znode,组成 YMB 服务的每个活动服务器都有一个临时 znode。 每个 YMB 服务器在节点下创建一个临时 znode,其负载和状态信息通过 ZooKeeper 提供组成员身份和状态信息。 禁止关闭和迁移等节点由构成该服务的所有服务器进行监控,并允许对 YMB 进行集中控制。 对于 YMB 管理的每个主题,主题目录都有一个子 znode。 这些主题 znode 具有子 znode,它们指示每个主题的主服务器和备份服务器以及该主题的订阅者。 主服务器和备用服务器 znode 不仅允许服务器发现负责主题的服务器,而且它们还管理 领导者选举(leader election) 和处理服务器崩溃。
4 ZooKeeper 实现
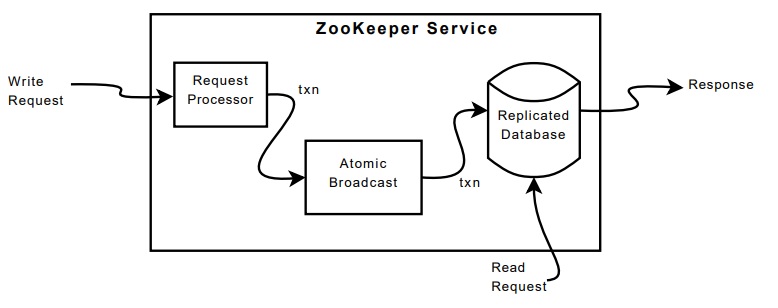
ZooKeeper 通过在组成服务的每个服务器上复制 ZooKeeper 数据来提供高可用性。 我们假设服务器因崩溃而失败,并且此类故障服务器稍后可能会恢复。 图 4 显示了 ZooKeeper 服务的高级组件。 收到请求后,服务器准备执行(请求处理器)。 如果这样的请求需要服务器之间的协调(写请求),那么它们使用协议协议(原子广播的实现),最后服务器提交对 ZooKeeper 数据库的更改, 并在集合的所有服务器之间完全复制。 在读取请求的情况下,快速读取本地数据库的状态并生成对请求的响应。
复制数据库是包含整个数据树的内存数据库。
树中的每个 znode 默认存储最大 1MB 的数据,但是这个最大值是一个配置参数,可以在具体案例。
为了可恢复性,我们有效地将更新记录到磁盘,并在将写入应用到内存数据库之前强制写入磁盘介质。
事实上,作为 Chubby [8],我们保留已提交操作的重放日志(在我们的例子中是预写日志)并生成内存数据库的定期快照。
每个 ZooKeeper 服务器都为客户端提供服务。 客户端仅连接到一台服务器以提交其请求。 如前所述,读取请求由每个服务器数据库的本地副本提供服务。 改变服务状态的请求,写请求,由协议协议处理。
作为协议协议的一部分,写请求被转发到单个服务器,称为领导者(leader)。 其余的 ZooKeeper 服务器,称为追随者(follower),从领导者接收由状态变化组成的消息提议,并就状态变化达成一致。
4.1 请求处理器
由于消息传递层是原子性的,我们保证本地副本永远不会发散,尽管在任何时间点某些服务器可能比其他服务器应用了更多的事务。 与客户端发送的请求不同,事务是幂等的。 当 leader 收到写入请求时,它会计算应用写入时系统的状态,并将其转换为捕获此新状态的事务。 必须计算未来状态,因为可能存在尚未应用到数据库的未完成事务。 例如,如果客户端执行条件 setData 并且请求中的版本号与正在更新的 znode 的未来版本号匹配,则服务生成一个 setDataTXN,其中包含新数据、新版本号和更新的时间戳。 如果出现错误,例如版本号不匹配或要更新的 znode 不存在,则生成一个 errorTXN。
4.2 原子性的广播
所有更新 ZooKeeper 状态的请求都会转发给领导者。
领导者执行请求并通过原子广播协议 Zab [24] 广播对 ZooKeeper 状态执行更改。
收到客户端请求的服务器在收到相应的状态变化的请求时响应客户端。
Zab 默认使用简单多数仲裁来决定提案,因此 Zab 和 ZooKeeper 只能在大多数服务器正确时才能工作
(即,集群中的总量为 2f+1 个服务器,我们可以容忍 f 个服务器故障)
为了实现高吞吐量,ZooKeeper 尝试保持完整的请求处理管道。 在处理管道的不同部分可能有数千个请求。 由于状态变化依赖于先前状态变化的应用,Zab 提供了比常规原子广播更强的顺序保证。 更具体地说,Zab 保证领导者广播的更改请求按照发送的顺序进行传递,并且在广播自己的更改之前,将先前领导者的所有更改传递给已建立的领导者。
有一些实现细节可以简化我们的实现并为我们提供出色的性能。 我们使用 TCP 进行传输,因此消息顺序由网络维护,这使我们能够简化我们的实现。 我们使用 Zab 选择的领导者作为 ZooKeeper 领导者,以便创建事务的相同过程也提出它们。 我们使用日志来跟踪建议作为内存数据库的预写日志,这样我们就不必将消息两次写入磁盘。
在正常操作期间,Zab 确实按顺序传递所有消息,并且只传递一次,但由于 Zab 不会持久记录每个传递的消息的 id,因此 Zab 可能会在恢复期间重新传递消息。 因为我们使用幂等交易,所以只要按顺序交付,多次交付是可以接受的。 事实上,ZooKeeper 要求 Zab 至少重新传递在上一个快照开始后传递的所有消息。
4.3 数据库副本
每个副本在 ZooKeeper 状态的内存中都有一个副本。 当 ZooKeeper 服务器从崩溃中恢复时,它需要恢复这个内部状态。 在服务器运行一段时间后,重放所有已传递的消息以恢复状态将花费非常长的时间,因此 ZooKeeper 使用定期快照,并且只需要从快照开始后重新传递消息。 我们称 ZooKeeper 快照为模糊快照,因为我们不锁定 ZooKeeper 状态来拍摄快照; 相反,我们对树进行深度优先扫描,以原子方式读取每个 znode 的数据和元数据并将它们写入磁盘。 由于生成的模糊快照可能应用了快照生成期间传递的状态更改的某些子集,因此结果可能与 ZooKeeper 在任何时间点的状态都不对应。 但是,由于状态更改是幂等的,只要我们按顺序应用状态更改两次就可以确定的恢复状态。
例如,假设在 ZooKeeper 数据树中,两个节点 /foo 和 /goo 分别具有值 f1 和 g1,并且在模糊快照开始时都处于版本 1,
状态变更流以如下形式到达:<htransactionType, path, value, new-version>
1 | |
处理这些状态更改后,/foo 和 /goo 分别具有版本 3 和 2 的值 f3 和 g2。
但是,模糊快照可能记录了 /foo 和 /foo 分别具有版本 3 和 1 的值 f3 和 g1,这不是 ZooKeeper 数据树的有效状态。
如果服务器崩溃并使用此快照恢复,并且 Zab 重新传递状态更改,则结果状态对应于崩溃前服务的状态。
4.4 客户端-服务器交互
当服务器处理写入请求时,它还会发送并清除与该更新对应的任何监视相关的通知。 服务器按顺序处理写入,不会同时处理其他写入或读取。 这确保了严格的通知连续性。 请注意,服务器在本地处理通知。 只有客户端连接到的服务器会跟踪和触发该客户端的通知。
读取请求在每个服务器本地处理。 每个读取请求都被处理并用一个 zxid 标记,该 zxid 对应于服务器看到的最后一个事务。 这个 zxid 定义了读请求相对于写请求的部分顺序。 通过在本地处理读取,我们获得了出色的读取性能,因为它只是本地服务器上的内存操作,没有磁盘活动或协议要运行。 这种设计选择是我们在读取占主导地位的工作负载下实现卓越性能目标的关键。
使用快速读取的一个缺点是不能保证读取操作的优先顺序。 也就是说,即使已提交对同一 znode 的更新操作,读取操作也可能返回陈旧值。 并非我们所有的应用程序都需要优先顺序,但对于确实需要它的应用程序,我们已经实现了 sync 源语。 该原语异步执行,并在所有未写入的操作写入本地副本后由领导者进行排序。 为了保证给定的读取操作返回最新更新的值,客户端调用 sync 源语,然后进行读取操作。 客户端操作的 FIFO 顺序保证以及 sync 源语的全局保证使读取操作可以反映出变更发布之前的任何更改。 在我们的实现中,我们不需要原子性的广播同步,因为我们使用基于领导者的算法,我们只需将同步操作放在领导者和执行同步调用的服务器之间的请求队列的末尾。 为了使其工作,追随者必须确保领导者仍然是领导者。 如果有待提交的事务进行提交,则服务器不会怀疑领导者。 如果待处理队列为空,则领导者需要发出并提交一个空事务并在该事务之后对 sync 源语进行排序。 这有一个很好的特性,即当领导者处于负载状态时,不会产生额外的广播流量。 在我们的实现中,超时设置为使领导者在追随者放弃他们之前意识到他们不是领导者,因此我们不会发出空事务。
ZooKeeper 服务器以 FIFO 顺序处理来自客户端的请求。 响应包括响应相关的 zxid。 甚至在没有活动的间隔期间的心跳消息也包括客户端连接到的服务器看到的最后一个 zxid。 如果客户端连接到新服务器,该新服务器通过检查客户端的最后一个 zxid 与其最后一个 zxid 来确保它的 ZooKeeper 数据视图至少与客户端的视图一样新。 如果客户端拥有比服务器更新的视图,则服务器不会与客户端重新建立会话,直到服务器的版本与客户端相同。 保证客户端能够找到另一个具有系统最新视图的服务器,因为客户端只能看到已复制到大多数 ZooKeeper 服务器的更改。 这种行为对于保证持久性很重要。
ZooKeeper 使用超时机制来检测客户端会话失败。 如果在会话超时内没有其他服务器从客户端会话接收任何内容,则领导者确定其存在故障。 如果客户端发送请求的频率足够高,则无需发送任何其他消息。 否则,客户端会在低活动期间发送心跳消息。 如果客户端无法与服务器通信以发送请求或心跳,它会连接到不同的 ZooKeeper 服务器以重新建立其会话。 为了防止会话超时,ZooKeeper 客户端库在会话空闲 s/3 ms 后发送心跳,如果 2s/3ms 没有收到服务器的消息,则切换到新服务器,其中 s 是会话超时参数以毫秒为单位。
5 评估
为了评估我们的系统,我们对系统饱和时的吞吐量以及各种注入故障的吞吐量变化进行了基准测试。 我们改变了组成 ZooKeeper 服务的服务器数量,但始终保持客户端数量不变。 为了模拟大量客户端,我们使用了 35 台机器来模拟 250 个并发客户端。
我们使用 Java 实现的 ZooKeeper 服务器,以及 Java 和 C 客户端。 对于这些实验,我们使用一个 Java 服务器将日志记录到一个磁盘上并在另一个磁盘上拍摄快照。 我们的基准测试客户端使用异步 Java 客户端 API,每个客户端至少有 100 个未完成的请求。 每个请求都包含对 1K 数据的读取或写入。 我们没有显示其他操作的基准,因为所有修改状态的操作的性能大致相同,非状态修改操作的性能(不包括同步)大致相同。 (同步的性能接近于轻量级写入,因为请求必须发送到领导者,但不会被广播。) 客户端每 300 毫秒发送一次已完成操作的计数,我们每 6 秒采样一次。 为了防止内存溢出,服务器会限制系统中并发请求的数量。 ZooKeeper 使用请求限制来防止服务器不堪重负。 对于这些实验,我们将 ZooKeeper 服务器配置为最多处理 2,000 个请求。
| 服务器数量 | 100% 读取 | 0% 读取 |
|---|---|---|
| 13 | 460k | 8k |
| 9 | 296k | 12k |
| 7 | 257k | 14k |
| 5 | 165k | 18k |
| 3 | 87k | 21k |
表 1:饱和系统的极端吞吐量性能
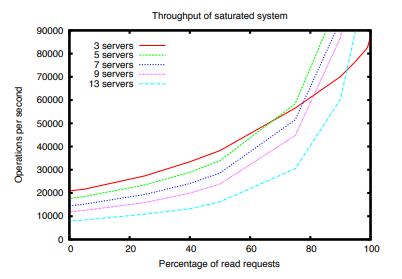
在图 5 中,我们显示了我们改变读写请求比率时的吞吐量,每条曲线对应于提供 ZooKeeper 服务的不同数量的服务器。 表 1 显示了读取负载极端情况下的数据。 读取吞吐量高于写入吞吐量,因为读取不使用原子广播。 该图还显示,服务器数量也对广播协议的性能产生负面影响。 从这些图中,我们观察到系统中的服务器数量不仅会影响服务可以处理的故障数量,还会影响服务可以处理的工作负载。 请注意,三台服务器的曲线与其他服务器的交叉率约为 60%。 这种情况不仅限于三服务器配置,并且由于启用了并行本地读取,所有配置都会发生这种情况。 然而,对于图中的其他配置无法观察到,因为我们已经限制了最大 y 轴吞吐量以提高可读性。
以下两个原因导致写请求比读请求花费更长的时间。
首先,写请求必须经过原子广播,这需要一些额外的处理并增加请求的延迟。
更长处理写入请求的另一个原因是服务器必须确保在将确认发送回领导者之前将事务记录到非易失性存储中。
原则上,这个要求是多余的,但对于我们的生产系统,我们用性能换取可靠性,因为 ZooKeeper 构成了应用程序的基本事实。
我们使用更多的服务器来容忍更多的故障。
我们通过将 ZooKeeper 数据划分为多个 ZooKeeper 集合来增加写入吞吐量。
Gray 等人先前已经观察到复制和分区之间的这种性能权衡 [12]。
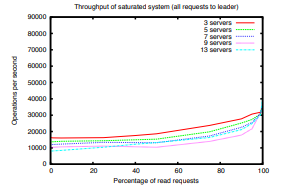
ZooKeeper 能够通过在构成服务的服务器之间分配负载来实现如此高的吞吐量。 由于我们宽松的一致性保证,我们可以分配负载。 Chubby 客户端将所有请求发送给领导者。 图 6 显示了如果我们不利用这种放松并强制客户端只连接到领导者会发生什么。 正如预期的那样,读取主导的工作负载的吞吐量要低得多,但即使是写入主导的工作负载,吞吐量也更低。 由服务客户端引起的额外 CPU 和网络负载会影响领导者协调提案广播的能力,进而对整体写入性能产生不利影响。
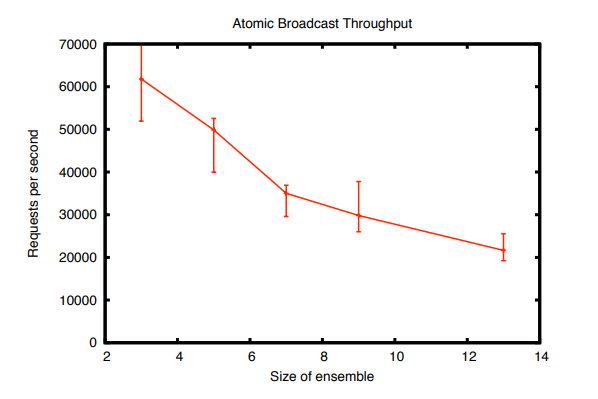
注:误差线表示最小值和最大值
原子广播协议完成了系统的大部分工作,因此比任何其他组件都更能限制 ZooKeeper 的性能。 图 7 显示了原子广播组件的吞吐量。 为了对其性能进行基准测试,我们通过直接在领导者处生成交易来模拟客户端,因此没有客户端连接或客户端请求和回复。 在最大吞吐量下,原子广播组件变得受 CPU 限制。 理论上,图 7 的性能将与 ZooKeeper 100% 写入的性能相匹配。 CPU 的争用将 ZooKeeper 的吞吐量降低到远低于孤立的原子广播组件。 因为 ZooKeeper 是一个关键的生产组件,到目前为止,我们对 ZooKeeper 的开发重点一直是正确性和健壮性。 通过消除额外副本、同一对象的多个序列化、更高效的内部数据结构等,有很多机会可以显着提高性能。
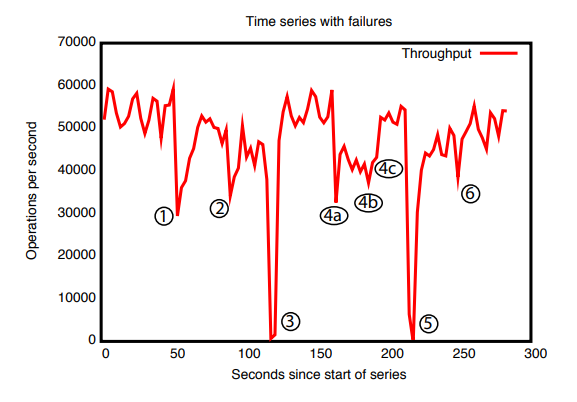
为了显示系统在注入故障时随时间的行为,我们运行了一个由 5 台机器组成的 ZooKeeper 服务。 我们运行了与之前相同的饱和基准测试,但这次我们将写入百分比保持在 30% 不变,这是我们预期工作负载的保守比例。 我们定期杀死一些服务器进程。 图 8 显示了随时间变化的系统吞吐量。 图中标注的事件如下:
- 一个追随者的故障和恢复
- 不同追随者的故障和恢复
- 领导者故障
- 前两个标记(a,b)中的两个追随者故障,在第三个标记©恢复;
- 领导者故障
- 领导者恢复
从这张图中有一些重要的观察结果。 首先,如果跟随者失败并快速恢复,那么即使出现故障,ZooKeeper 也能够维持高吞吐量。 单个跟随者的失败并不会阻止服务器形成仲裁,并且只会大致降低服务器在失败前处理的读取请求份额的吞吐量。 其次,我们的领导者选举算法能够足够快地恢复以防止吞吐量大幅下降。 在我们的观察中,ZooKeeper 花费不到 200 毫秒的时间来选举一个新的领导者。 因此,尽管服务器在几分之一秒内停止服务请求,但由于我们的采样周期,我们没有观察到零吞吐量,这是几秒的数量级。 第三,即使追随者需要更多时间来恢复,一旦他们开始处理请求,ZooKeeper 也能够再次提高吞吐量。 在事件 1、2 和 4 之后我们没有恢复到完整吞吐量级别的一个原因是客户端仅在与跟随者的连接中断时才切换跟随者。 因此,在事件 4 之后,客户端不会重新分配自己,直到领导者在事件 3 和 5 中失败。 在实践中,随着客户的来来去去,这种不平衡会随着时间的推移而自行解决。
5.2 请求延迟
为了评估请求的延迟,我们创建了一个以 Chubby 基准 [6] 为模型的基准。
我们创建一个工作进程,它只是发送一个创建操作,然后等待它完成,之后发送一个新节点的异步删除请求,然后开始下一个创建。
我们相应地改变了进程的数量,对于每次运行,我们让每个进程创建 50,000 个节点。
我们通过将完成的创建请求数除以所有进程完成所需的总时间来计算吞吐量。
| 工作进程数量 | 3台服务器 | 5台服务器 | 7台服务器 | 9台服务器 |
|---|---|---|---|---|
| 1 | 776 | 748 | 758 | 711 |
| 10 | 2074 | 1832 | 1572 | 1540 |
| 20 | 2740 | 2336 | 1934 | 1890 |
表 2:创建每秒处理的请求
表 2 显示了我们的基准测试结果。 创建请求包括 1K 数据,而不是 Chubby 基准测试中的 5 个字节,以更好地符合我们的预期用途。 即使有这些更大的请求,ZooKeeper 的吞吐量也比 Chubby 公布的吞吐量高出 3 倍以上。 单个 ZooKeeper worker 基准测试的吞吐量表明,三台服务器的平均请求延迟为 1.2ms,9 台服务器为 1.4ms。
5.3 屏障的性能表现
在这个实验中,我们依次执行了许多屏障来评估使用 ZooKeeper 实现的原语的性能。 对于给定数量的障碍 b,每个客户端首先进入所有 b 个障碍,然后依次离开所有 b 个障碍。 当我们使用第 2.4 节的双屏障算法时,客户端首先等待所有其他客户端执行 enter() 过程,然后再进入下一个调用(类似于 leave())。
| 屏障数量 | 50 个客户端 | 100 个客户端 | 200 个客户端 |
|---|---|---|---|
| 200 | 9.4 | 19.8 | 41.0 |
| 400 | 16.4 | 34.1 | 62.0 |
| 800 | 28.9 | 55.9 | 112.1 |
| 1600 | 54.0 | 102.7 | 234.4 |
我们在表 3 中报告了我们的实验结果。 在这个实验中,我们有 50、100 和 200 个客户端连续进入 b 个障碍,b ∈ {200, 400, 800, 1600}。 尽管一个应用程序可以有数千个 ZooKeeper 客户端,但通常只有更小的子集参与每个协调操作,因为客户端通常根据应用程序的细节进行分组。
该实验的两个有趣观察结果是,处理所有屏障的时间与屏障的数量大致呈线性增长,这表明对数据树同一部分的并发访问不会产生任何意外延迟,并且延迟与增加的客户端数量成正比。 事实上,我们观察到,即使客户端以锁步方式进行,在所有情况下,屏障操作(进入和离开)的吞吐量在每秒 1,950 到 3,100 次操作之间。 在 ZooKeeper 操作中,这对应于每秒 10,700 到 17,000 次操作之间的吞吐量值。 由于在我们的实现中,读取与写入的比率为 4:1(读取操作的 80%),与 ZooKeeper 可以实现的原始吞吐量(根据图 5 超过 40,000)相比,我们的基准代码使用的吞吐量要低得多。 这是因为客户端在等待其他客户端。
6 相关的工作
ZooKeeper 的目标是提供一种服务,以缓解分布式应用程序中协调进程的问题。 为了实现这个目标,它的设计使用了以前的协调服务、容错系统、分布式算法和文件系统的思想。
我们并不是第一个提出分布式应用程序协调系统的人。
一些早期系统为事务应用程序 [13] 和在计算机集群中共享信息 [19] 提出了分布式锁服务。
最近,Chubby 提出了一个系统来管理分布式应用程序的咨询锁 [6]。
Chubby 分享了 ZooKeeper 的几个目标。
它还具有类似文件系统的接口,并使用协议协议来保证副本的一致性。
但是,ZooKeeper 不是锁服务。
客户端可以使用它来实现锁,但它的 API 中没有锁操作。
与 Chubby 不同,ZooKeeper 允许客户端连接到任何 ZooKeeper 服务器,而不仅仅是领导者。
ZooKeeper 客户端可以使用其本地副本来提供数据和管理 watches,因为它的一致性模型比 Chubby 宽松得多。
这使得 ZooKeeper 能够提供比 Chubby 更高的性能,允许应用程序更广泛地使用 ZooKeeper。
文献中提出了容错系统,目的是减轻构建容错分布式应用程序的问题。
一种早期系统是 ISIS [5]。
ISIS 系统将抽象类型规范转化为容错的分布式对象,从而使容错机制对用户透明。
Horus [30] 和 Ensemble [31] 是从 ISIS 演变而来的系统。
ZooKeeper 采用了 ISIS 虚拟同步的概念。
最后,Totem 在利用局域网硬件广播的体系结构中保证消息传递的总顺序 [22]。
ZooKeeper 与各种网络拓扑一起工作,这促使我们依赖服务器进程之间的 TCP 连接,而不假设任何特殊的拓扑或硬件功能。
我们也不公开 ZooKeeper 内部使用的任何集成通信。
构建容错服务的一项重要技术是状态机复制 [26],而 Paxos [20] 是一种算法,可以为异步系统有效实现复制状态机。
我们使用的算法具有 Paxos 的一些特征,但它将共识所需的事务日志记录与数据树恢复所需的预写日志记录相结合,以实现高效的实现。
目前已经存在用于实现 Byzantine 灾难冗余复制状态机的协议 [7, 10, 18, 1, 28]。
ZooKeeper 不假设服务器可以是 Byzantine 式的,但我们确实采用了校验和和健全性检查等机制来捕获非恶意的 Byzantine 式故障。
克莱门特等人讨论了一种在不修改当前服务器代码库的情况下使 ZooKeeper 完全具有 Byzantine 灾难冗余的方法 [9]。
迄今为止,我们还没有观察到使用完全 Byzantine 灾难冗余协议可以防止的生产故障。 [29]。
Boxwood [21] 是一个使用分布式锁服务器的系统。
Boxwood 为应用程序提供了更高级别的抽象,它依赖于基于 Paxos 的分布式锁服务。
和 Boxwood 一样,ZooKeeper 也是一个用于构建分布式系统的组件。
但是,ZooKeeper 具有高性能要求,在客户端应用程序中使用更广泛。
ZooKeeper 公开应用程序用于实现更高级别原语的较低级别原语。
ZooKeeper 类似于一个小型文件系统,但它仅提供文件系统操作的一小部分,并添加了大多数文件系统中不存在的功能,例如排序保证和条件写入。
然而,ZooKeeper 监视在本质上类似于 AFS [16] 的缓存回调。
Sinfonia [2] 引入了迷你交易,这是一种构建可扩展分布式系统的新范例。
Sinfonia 旨在存储应用程序数据,而 ZooKeeper 存储应用程序元数据。
ZooKeeper 将其状态完全复制并保存在内存中,以实现高性能和一致的延迟。
我们使用像操作和排序这样的文件系统可以实现类似于小交易的功能。
znode 是一种方便的抽象,我们可以在其上添加监视,这是 Sinfonia 中缺少的功能。
Dynamo [11] 允许客户端在分布式键值存储中获取和放置相对少量(小于 1M)的数据。
与 ZooKeeper 不同,Dynamo 中的密钥空间不是分层的。
Dynamo 也不为写入提供强大的持久性和一致性保证,而是解决读取冲突。
DepSpace [4] 使用元组空间提供Byzantine 灾难冗余服务。
像 ZooKeeper 一样,DepSpace 使用简单的服务器接口在客户端实现强同步原语。
虽然 DepSpace 的性能远低于 ZooKeeper,但它提供了更强的容错和机密性保证。
7 结论
ZooKeeper 通过向客户端公开无等待对象,采用无等待方法来解决分布式系统中协调进程的问题。 我们发现 ZooKeeper 对无论是雅虎内部或外部的多个应用程序非常有用。 ZooKeeper 通过使用带 watches 的快速读取(两者都由本地副本提供服务)为工作负载主要为读取的应用实现每秒数十万次操作的吞吐量值。 尽管我们对读取和监视的一致性保证似乎很弱,但我们已经通过我们的用例表明,这种组合允许我们在客户端实现高效和复杂的协调协议, 即使读取不是优先顺序的并且使用免等待的数据结构进行实现。 事实证明,免等待特性对于高性能至关重要。
尽管我们只描述了几个应用程序,但还有许多其他应用程序使用 ZooKeeper。 我们相信这样的成功是由于其简单的接口以及可以通过该接口实现的强大抽象。 此外,由于 ZooKeeper 的高吞吐量,应用程序可以广泛使用它,而不仅仅是粗粒度的锁定。
致谢
1 | |
参考文献
[1] M. Abd-El-Malek, G. R. Ganger, G. R. Goodson, M. K. Reiter, and J. J. Wylie.
Fault-scalable byzantine fault-tolerant services.
In SOSP ’05: Proceedings of the twentieth ACM symposium on Operating systems principles, pages 59–74, New York, NY, USA, 2005. ACM.
[2] M. Aguilera, A. Merchant, M. Shah, A. Veitch, and C. Karamanolis.
Sinfonia: A new paradigm for building scalable distributed systems.
In SOSP ’07: Proceedings of the 21st ACM symposium on Operating systems principles, New York, NY, 2007.
[3] Amazon. Amazon simple queue service.
http://aws.amazon.com/sqs/, 2008.
[4] A. N. Bessani, E. P. Alchieri, M. Correia, and J. da Silva Fraga.
Depspace: A byzantine fault-tolerant coordination service.
In Proceedings of the 3rd ACM SIGOPS/EuroSys European Systems Conference - EuroSys 2008, Apr. 2008.
[5] K. P. Birman.
Replication and fault-tolerance in the ISIS system.
In SOSP ’85: Proceedings of the 10th ACM symposium on Operating systems principles, New York, USA, 1985. ACM Press.
[6] M. Burrows.
The Chubby lock service for loosely-coupled distributed systems.
In Proceedings of the 7th ACM/USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2006.
[7] M. Castro and B. Liskov.
Practical byzantine fault tolerance and proactive recovery.
ACM Transactions on Computer Systems, 20(4), 2002.
[8] T. Chandra, R. Griesemer, and J. Redstone.
Paxos made live: An engineering perspective.
In Proceedings of the 26th annual ACM symposium on Principles of distributed computing (PODC), Aug.2007.
[9] A. Clement, M. Kapritsos, S. Lee, Y. Wang, L. Alvisi, M. Dahlin, and T. Riche.
UpRight cluster services.
In Proceedings of the 22 nd ACM Symposium on Operating Systems Principles (SOSP), Oct. 2009.
[10] J. Cowling, D. Myers, B. Liskov, R. Rodrigues, and L. Shira.
Hqreplication: A hybrid quorum protocol for byzantine fault tolerance.
In SOSP ’07: Proceedings of the 21st ACM symposium on Operating systems principles, New York, NY, USA, 2007.
[11] G. DeCandia, D. Hastorun, M. Jampani, G. Kakulapati, A. Lakshman, A. Pilchin, S. Sivasubramanian,
P. Vosshall, and W. Vogels.
Dynamo: Amazons highly available key-value store.
In SOSP ’07: Proceedings of the 21st ACM symposium on Operating systems principles, New York, NY, USA, 2007. ACM Press.
[12] J. Gray, P. Helland, P. O’Neil, and D. Shasha.
The dangers of replication and a solution.
In Proceedings of SIGMOD ’96, pages 173–182, New York, NY, USA, 1996. ACM.
[13] A. Hastings.
Distributed lock management in a transaction processing environment.
In Proceedings of IEEE 9th Symposium on Reliable Distributed Systems, Oct. 1990.
[14] M. Herlihy.
Wait-free synchronization.
ACM Transactions on Programming Languages and Systems, 13(1), 1991.
[15] M. Herlihy and J. Wing.
Linearizability: A correctness condition for concurrent objects.
ACM Transactions on Programming Languages and Systems, 12(3), July 1990.
[16] J. H. Howard, M. L. Kazar, S. G. Menees, D. A. Nichols, M. Satyanarayanan, R. N. Sidebotham, and M. J. West.
Scale and performance in a distributed file system.
ACM Trans. Comput. Syst., 6(1), 1988.
[17] Katta.
Katta - distribute lucene indexes in a grid.
http://katta.wiki.sourceforge.net/, 2008.
[18] R. Kotla, L. Alvisi, M. Dahlin, A. Clement, and E. Wong.
Zyzzyva: speculative byzantine fault tolerance.
SIGOPS Oper. Syst. Rev., 41(6):45–58, 2007.
[19] N. P. Kronenberg, H. M. Levy, and W. D. Strecker.
Vaxclusters (extended abstract): a closely-coupled distributed system.
SIGOPS Oper. Syst. Rev., 19(5), 1985.
[20] L. Lamport.
The part-time parliament.
ACM Transactions on Computer Systems, 16(2), May 1998.
[21] J. MacCormick, N. Murphy, M. Najork, C. A. Thekkath, and L. Zhou.
Boxwood: Abstractions as the foundation for storage infrastructure.
In Proceedings of the 6th ACM/USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2004.
[22] L. Moser, P. Melliar-Smith, D. Agarwal, R. Budhia, C. LingleyPapadopoulos, and T. Archambault.
The totem system.
In Proceedings of the 25th International Symposium on Fault-Tolerant Computing, June 1995.
[23] S. Mullender, editor.
Distributed Systems, 2nd edition.
ACM Press, New York, NY, USA, 1993.
[24] B. Reed and F. P. Junqueira.
A simple totally ordered broadcast protocol.
In LADIS ’08: Proceedings of the 2nd Workshop on Large-Scale Distributed Systems and Middleware, pages 1–6,
New York, NY, USA, 2008. ACM.
[25] N. Schiper and S. Toueg.
A robust and lightweight stable leader election service for dynamic systems.
In DSN, 2008.
[26] F. B. Schneider.
Implementing fault-tolerant services using the state machine approach: A tutorial.
ACM Computing Surveys, 22(4), 1990.
[27] A. Sherman, P. A. Lisiecki, A. Berkheimer, and J. Wein.
ACMS:The Akamai configuration management system.
In NSDI, 2005.
[28] A. Singh, P. Fonseca, P. Kuznetsov, R. Rodrigues, and P. Maniatis.
Zeno: eventually consistent byzantine-fault tolerance.
In NSDI’09: Proceedings of the 6th USENIX symposium on Networked systems design and implementation, pages 169–184,
Berkeley, CA, USA, 2009. USENIX Association.
[29] Y. J. Song, F. Junqueira, and B. Reed.
BFT for the skeptics.
http://www.net.t-labs.tu-berlin.de/˜petr/BFTW3/abstracts/talk-abstract.pdf.
[30] R. van Renesse and K. Birman.
Horus, a flexible group communication systems.
Communications of the ACM, 39(16), Apr.1996.
[31] R. van Renesse, K. Birman, M. Hayden, A. Vaysburd, and D. Karr.
Building adaptive systems using ensemble. Software- Practice and Experience, 28(5), July 1998.