ureplicator-apache-kafka-replicator
uReplicator: Uber Engineering’s Robust Apache Kafka Replicator(中文翻译版)
简介
Uber 罗列了社区的 MirrorMaker 工具的一些缺陷以及自研工具(uReplicator)的应对实现方法。所以此处将此博文进行翻译整理。
Uber 的数据分析工作流
在 Uber,使用 Apache Kafka 作为连接生态系统中不同部分的数据管道。从乘客和驾驶员应用程序中收集系统和应用程序日志以及事件数据。然后,通过 Kafka 将这些数据提供给各种下游消费者。
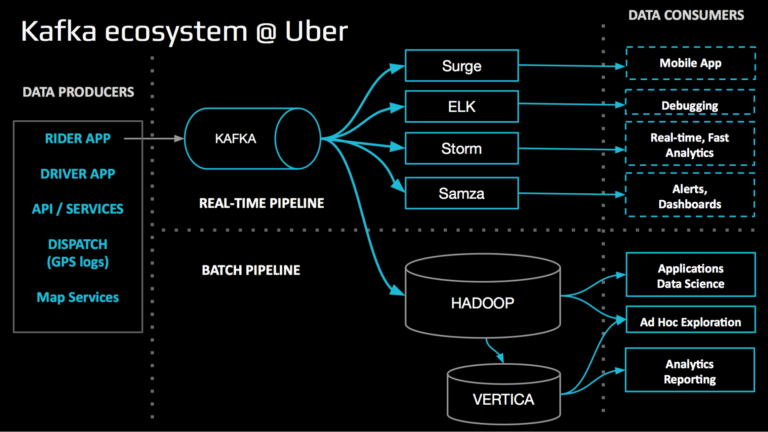
Kafka 中的数据同时提供实时管道和批处理管道。前一个数据用于计算业务指标、调试、警报和仪表板等活动。批处理管道数据更具探索性,例如将 ETL 转换为 Apache Hadoop 和 HP Vertica。
在本文中,将介绍 Uber 的开源解决方案 UreReplicator,该解决方案用于以健壮可靠的方式复制 Apache Kafka 数据。该系统扩展了 Kafka MirrorMaker 的原始设计,专注于极高的可靠性、零数据丢失保证和易操作性。uReplicator 自2015年11月开始投入生产,是 Uber 多数据中心基础设施的关键组成部分。
什么是 MirrorMaker,为什么需要它
鉴于 Uber 内部大量使用 Kafka,在不同的数据中心使用多个集群。一些用例需要查看这些数据的全局视图。例如,为了计算与出行次数相关的业务指标,需要从所有数据中心收集信息,并在一个地方进行分析。为了实现这一点,之前一直使用 Kafka 软件包附带的开源 MirrorMaker 工具跨数据中心复制数据,如下所示。
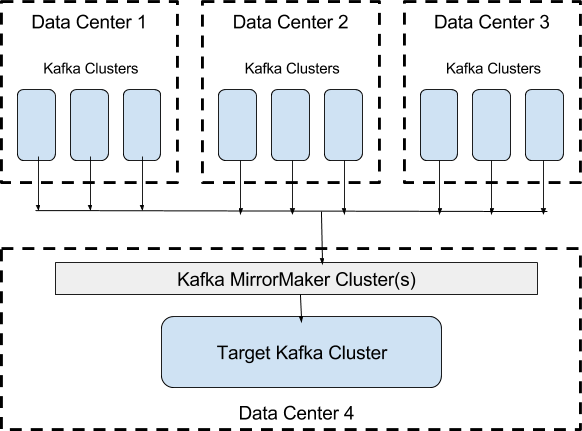
MirrorMaker(首次在 Kafka 0.8.2 版本引入)本身非常简单。它使用高级 Kafka 消费者从源集群获取数据,然后将该数据馈送到 Kafka 生产者以将其转储到目标集群。
在 Uber 遇到的 Kafka MirrorMaker 缺陷
尽管初始的 MirrorMaker 设置已经满足了需求,但很快就遇到了可伸缩性问题。随着主题数量和数据速率(bytes/second)的增长,就开始出现数据交付延迟或丢失进入聚合集群的数据,从而导致生产环境问题,降低了数据质量。针对 Uber 特定用例的现有 MirrorMaker 工具(从 0.8.2 开始)的一些主要问题如下所示:
不可接受的重平衡(rebalancing)
如前所述,每个 MirrorMaker 工作线程使用一个高级消费者。这些消费者经常经历一个再平衡的过程。他们相互协商决定谁拥有哪个主题分区(通过 Apache ZooKeeper完成)。这个过程可能需要很长时间;在某些情况下,我们观察到大约 5-10 分钟的重平衡过程。这是一个问题,因为它违反了端到端延迟保证。此外,消费者可以在 32 次再平衡尝试后放弃,永远陷入停止状态。不幸的是,我们亲眼看到这种情况发生过几次。在每次尝试重新平衡后都会看到类似的流量模式:
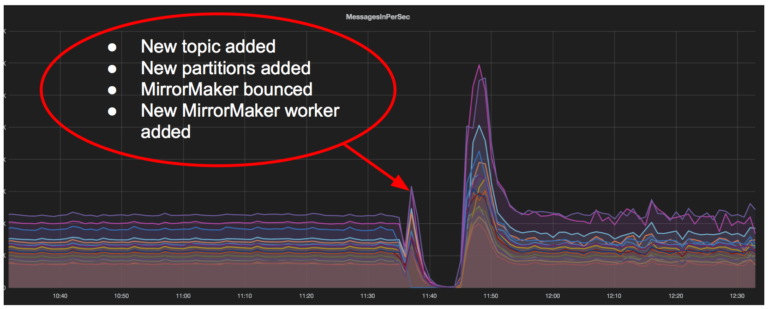
在重新平衡期间的停止活动之后,MirrorMaker 有大量积压的数据需要处理。这导致目标集群和所有下游消费者的流量激增,导致生产中断和增加端到端延迟。
添加主题困难
在 Uber,必须在 MirrorMaker 中指定一个主题白名单,以控制通过 WAN 链路的数据流量。对于 Kafka MirrorMaker 来说这个白名单是完全静态的,需要重新启动 MirrorMaker 集群来添加新的主题。重启成本过于高昂,因为它迫使高层消费者进行重新平衡。
可能造成数据丢失
旧的 MirrorMaker 有一个问题(在最新版本中似乎已经被修复了),自动的位移提交可能会导致数据丢失。高级消费者会自动提交已经获取到的消息的偏移量。如果在 MirrorMaker 未能验证其是否将消息正常写入目标集群之前发生故障,则这些消息则会被丢弃。
元数据同步问题
Uber 的工程师在更新配置的方式上也遇到了操作问题。要从白名单中添加或删除主题,Uber 的工程师在一个配置文件中列出了所有最终的主题名称,该文件在 MirrorMaker 初始化期间读取。有时,配置无法在其中一个节点上更新。这导致了整个集群的崩溃,因为不同的 MirrorMaker 工作人员在要复制的主题列表上没有达成一致。
为什么研发 uReplicator
Uber 的工程师构思了以下几种方案来解决上述问题:
方案 A:将数据分发进多个 MirrorMaker 集群中
上面列出的大多数问题都是由高级消费者再平衡过程造成的。减少其影响的一种方法是限制一个 MirrorMaker 集群复制的主题分区的数量。因此,可以拆分成几个 MirrorMaker 集群,每个集群复制要聚合的主题子集。
优点:
- 新增主题简单,只需要新增一个集群就可以了。
- 重启速度也会很快
缺点:
- 这是另一个运维噩梦:必须部署和维护多个集群。
方案 B:使用 Apache Samza 进行复制
由于问题在于高级消费者(从0.8.2开始),另一种解决方案是使用 Kafka SimpleConsumer 并添加缺少的领导人选举和分区分配功能。Apache Samza 是一个流处理框架,它已经静态地将分区分配给工作线程。然后,可以简单地使用 Samza 作业将数据复制和聚合到目标。
优点:
- 稳定可靠
- 便于维护,使用一个任务可以复制多个主题
- 重启任务时造成的影响小
缺点:
- 实现模式比较僵化,需要重启任务才能新增或删除话题
- 需要重启任务才能新增工作线程
- 主题扩展需要显式处理。
方案 C:使用 Apache Helix-based Kafka consumer
最终方案是使用基于 Helix-based Kafka consumer。在本例中,使用 Apache Helix 将分区分配给工作线程,每个工作线程使用 Simple Consumer 复制数据。
优点:
- 添加和删除主题非常简单
- 向 MirrorMaker 集群添加和删除节点非常简单。
- 永远不需要出于操作原因重新启动集群(仅在升级时重启)。
- 可靠稳定
缺点:
- 引入了对 Helix 的依赖。(这是可以接受的,因为 Helix 本身非常稳定,可以将一个 Helix 集群用于多个 MirrorMaker 集群。)
uReplicator 概览
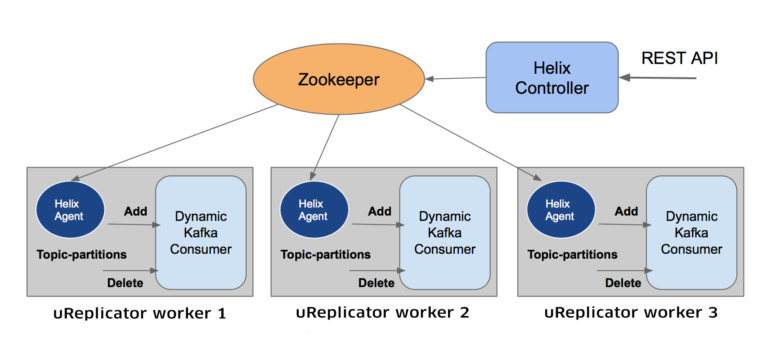
uReplicator 的各种组件以不同的方式工作,以实现可靠性和稳定性:
- Helix uReplicator 控制器实际上是一个节点群集,它有几个职责:
- 为每个工作进程分配和分配主题分区
- 处理主题/分区的添加/删除
- 处理 uReplicator 工作进程的添加/删除
- 检测节点故障并重新分配那些特定的主题分区
控制器使用 ZooKeeper 来完成所有这些任务。它还公开了一个简单的 REST API,以便添加/删除/修改要镜像的主题。
- uReplicator 工作线程,类似于Kafka MirrorMaker 功能中的工作进程,将一组主题和分区从源集群复制到目的集群。uReplicator 控制器决定 uReplicator 的分配,而不是重新平衡过程。此外,抛弃了 Kafka 高级消费者,而是使用称为 DynamicKafkaConsumer 的简化版本。
- 只要发生了变化(话题分区的增加/删除) Helix 客户端会通知每个 uReplicator 工作节点。反之一样,Helix 也会通知 DynamicKafkaConsumer 添加/删除主题分区。
- 每个 uReplicator 工作线程上都存在一个 DynamicKafkaConsumer 实例,它是 Kafka 高级消费者的魔改版本。它删除了重新平衡部分,并添加了一种动态添加/删除主题分区的机制。
假设向现有的 uReplicator 集群添加一个新主题。事件流程如下所示:
- Kafka 管理员使用以下命令将新主题添加到控制器:
1 | |
- uReplicator 控制器计算 testTopic 的分区数量,并将主题分区映射到活动的工作线程。然后更新 ZooKeeper 元数据以反映此映射。
- 每个相应的 Helix 客户端都会收到一个回调,通知添加这些主题分区。反过来,客户端也会引用DynamicKafkaConsumer 的 addFetcherForPartitions 功能 。
- 该 DynamicKafkaConsumer 随后注册这些新的分区,找到相应的领导经纪人,并将它们添加到提取器线程来启动数据镜像。
有关实现的更多详细信息,请参阅 uReplicator Design wiki。
对整体稳定性的影响
自从大约八个月前 Uber 上首次推出 uReplicator 以来,还没有看到一个产品出现问题(与实施前几乎每周都会出现的某种停机形成对比)。下图描述了在生产环境中将新主题添加到 MirrorMaker 白名单的场景。第一个图显示每个 uReplicator 工作人员拥有的总主题分区。每添加一个新主题,此计数就会增加。

第二个图显示流向目标群集的相应 uReplicator 流量。没有出现 Kafka MirrorMaker 一样的有一段时间的停止消费或负载峰值:

总的来说,uReplicator 的优势如下:
- 稳定:重新平衡现在仅在启动期间以及添加或删除节点时发生。此外,它只影响主题分区的一个子集,而不是像以前那样导致完全不活动。
- 更好的扩展性:现在向现有集群添加新节点要简单得多。由于分区分配现在是静态的,可以智能地仅将分区的子集移动到新节点。其他主题分区不受影响。
- 操作更简单:uReplicator 支持动态白名单。现在在添加/删除/扩展 Kafka 主题时不需要重新启动集群。
- 零数据丢失:uReplicator 保证零数据丢失,因为它仅在数据被持久化到目标集群后才提交检查点。
参考资料
uReplicator: Uber Engineering’s Robust Apache Kafka Replicator