MapReduce shuffle
MapReduce shuffle
简介
在 Hadoop 中 MapReduce 应用通常实现了 Mapper 和 Reducer 接口来提供 Map 和 Reduce 方法。 这也就构成了整个任务的核心。
注:在 Mapper 中还会发生文件溢写、排序、合并等操作,这些内容在《Hadoop 权威指南》中统一的被划分到了 shuffle 章节一同介绍。
Reducer 则主要有以下三个阶段:
- shuffle
- sort
- reduce
在官方文档中是这样描述 shuffle 的:
1 | |
Reducer 所需的输入是经过排序的 Mapper 输出。 在这个阶段,MapReduce 框架通过 HTTP 的方式获取所有 Mapper 输出的相关分区。
而在《Hadoop 权威指南》中的描述则是这样的:
MapReduce 确保每个 Reducer 的输入都是按键排序的。 系统执行排序的过程(即将 Map 输出作为输入传入 Reducer) 称为 shuffle。
注:以下是书中的标注
事实上,shuffle 这个说法并不准确。因为在某些语境中,它只代表 Reduce 任务获取 Map 输出的过程。 在这一小节,我们将其理解为从 Map 产生输出到 Reduce 消化输入的整个过程。
整体流程梳理
虽然说官方文档仅仅将 shuffle 归类到了 Reducer 中,但是此处会参照《Hadoop 权威指南》中的表述方式梳理具体流程。
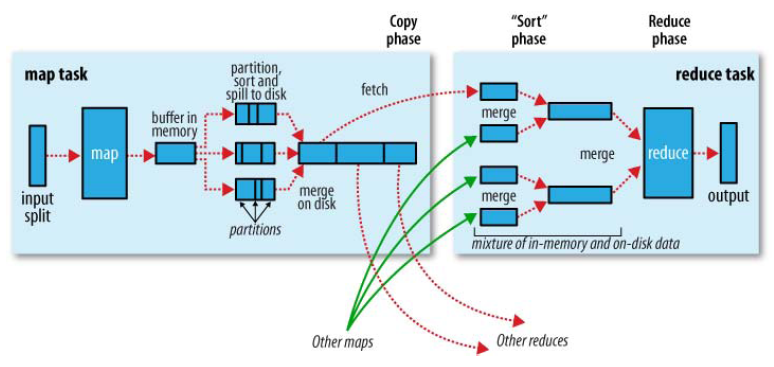
Map 端流程
Map 函数产生输出时,并不是简单地将它写到磁盘。而是利用缓冲的方式写到内存,并出于效率的考虑进行预排序。详见下图:
每个 Map 任务都有一个环形内存缓冲区用于储存任务输出。
一旦缓冲内容达到设定的阈值(io.sort.spill.percent) 一个后台线程便开始把内容溢写 (spill) 到磁盘。
在溢写的过程中如果缓冲区被填满则 Map 会阻塞直到写入完成。
在写入磁盘之前,线程首先根据数据最终要传输的 Reducer 把数据划分成相应的分区(partition)。 在每个分区中,后台线程按键进行内部排序,如果有 combiner,它就在排序后的输出上运行。 运行 combiner 会使的 Map 输出结果更紧凑,因此减少写到磁盘的数据和传递给 Reducer 的数据。
每次溢出都会产生新的文件,在任务完成后会将所有文件进行合并和排序。
如果至少存在 3 个溢出文件,combiner 会在数据文件写入磁盘之前运行。
Reduce 端流程
Map 的输出会在 task tracker 的本地磁盘上。 task tracker 会为分区文件运行 Reduce 任务。 Reducer 会通过 HTTP 的方式得到输出文件的分区 。
如果 Map 输出的数据量相当小,则会被复制到 Reduce 任务的 JVM 内存中,否则将会被复制到磁盘。
一旦内存缓冲区达到阈值大小(maperd.job.suhffle.input.buffer.percent)
或达到 Map 输出阈值(maperd.inmem.merge.threshold),则合并溢写到磁盘中。
如果指定 combiner 则在合并期间运行它来降低写入硬盘的数据量。
随着磁盘上副本增多,后台线程会将它们合并为更大的、排好序的文件。 这会为后面的合并节省一些时间。 注意,为了合并,压缩的 Map 输出都必须在内存中被解压缩。
复制完所有 Map 输出后,Reduce 任务进入排序阶段(更恰当的说法是合并阶段,因为排序是在 Map 端进行的),这个阶段将合并 Map 输出, 维持其顺序排序。
在最后阶段即 Reduce 阶段,直接把数据输入 Reduce 函数,从而省略一次读取和写入操作的行程。 最后的合并可以来自内存和磁盘片段。
在 Reduce 阶段,对已排序输出中的每个键调用 Reduce 函数。 此阶段的输出直接写到输出文件系统,一般为 HDFS。 如果使用 HDFS,由于 task tracker 节点(或者节点管理器)也运行数据节点,所以第一个文件块的副本被写入到本地磁盘。
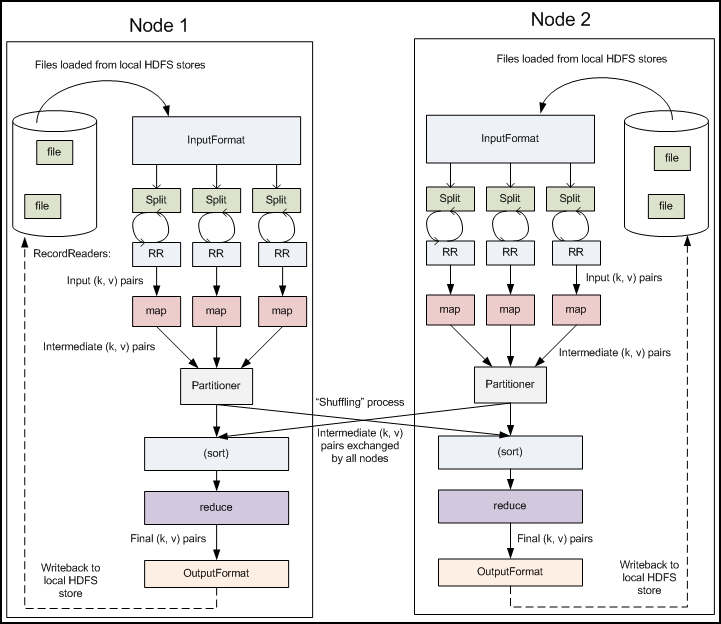
Word Count 数据流样例
参考资料
《Hadoop 权威指南:大数据的存储与分析》